Definition of neural network lays the foundation for understanding these complex systems. Neural networks, inspired by the human brain, are powerful tools used in various fields. From image recognition to natural language processing, they are revolutionizing technology. This exploration will delve into the core components, types, learning processes, and applications of neural networks.
This detailed guide will cover everything from the basic architecture of a neural network to advanced concepts like different learning algorithms and evaluation metrics. We’ll also examine the strengths and weaknesses of these powerful tools and their impact on various industries. Get ready for a comprehensive journey into the fascinating world of neural networks!
Introduction to Neural Networks: Definition Of Neural Network
Neural networks are a powerful class of algorithms inspired by the structure and function of the human brain. They consist of interconnected nodes, or neurons, organized in layers, enabling them to learn complex patterns and relationships from data. This learning process allows neural networks to make predictions and decisions with minimal human intervention, making them valuable tools in various fields.
Basic Components of a Neural Network
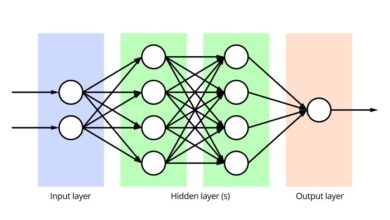
Neural networks are composed of interconnected nodes, often called neurons. These neurons are organized into layers: an input layer, one or more hidden layers, and an output layer. The input layer receives the data, which is then processed through the hidden layers, and finally, the output layer produces the result. Connections between neurons have associated weights, which are adjusted during the learning process.
These weights determine the strength of the connection between neurons, and they play a crucial role in the network’s ability to learn and generalize. Activation functions introduce non-linearity to the network, allowing it to model complex relationships in the data.
Historical Context of Neural Networks
The concept of neural networks emerged in the 1940s and 1950s, with early models inspired by biological neurons. These early networks, however, were limited by computational power and lacked sufficient training data. Significant advancements in the field occurred in the 1980s with the introduction of backpropagation, a powerful algorithm for training multilayer neural networks. The resurgence of neural networks in recent years is driven by the availability of large datasets and powerful computing resources.
Neural networks, essentially interconnected nodes processing information, are fascinating. But sometimes, understanding complex systems like these requires us to step back and acknowledge the intricate, often overlooked, physical aspects of ourselves. Thinking about how we “properly grieve our bodies,” as explored in this insightful essay, properly grieving our bodies essay , can offer a unique lens through which to view the intricate connections within our own biological neural networks.
This awareness of our physical selves, ultimately, can inform how we understand and approach the concept of neural networks in the abstract.
Different Types of Neural Networks
Neural networks come in various architectures, each suited for specific tasks. Understanding these different types is crucial for selecting the appropriate network for a given problem. Feedforward networks process data in one direction, from input to output, without loops. Recurrent networks, on the other hand, have loops in their architecture, allowing them to process sequential data and maintain internal state.
This allows them to consider the context of past inputs when making predictions. Other types, such as convolutional neural networks (CNNs), are designed to process grid-like data, like images.
Types of Neural Networks Table
| Type | Architecture | Applications |
|---|---|---|
| Feedforward | Data flows in one direction, from input to output. No loops. | Image classification, object detection, spam filtering, and more. |
| Recurrent (RNNs) | Has loops in the architecture, allowing it to process sequential data and maintain internal state. | Natural language processing (NLP), machine translation, speech recognition, time series forecasting. |
| Convolutional (CNNs) | Designed to process grid-like data (images, video). | Image recognition, image segmentation, object detection in images and videos. |
Fundamental Concepts
Delving deeper into the workings of neural networks, we now explore their fundamental building blocks. Understanding these concepts is crucial for grasping how these networks learn and make predictions. These components, including nodes, connections, activation functions, weight adjustments, and backpropagation, are the engines driving the network’s performance.Neural networks are inspired by the structure of the human brain, mimicking its interconnectedness to solve complex problems.
The fundamental concepts we’ll discuss provide a framework for understanding this intricate process.
Nodes and Connections
Neural networks are composed of interconnected nodes, often organized in layers. Each node receives input signals from other nodes, processes them, and passes the results to subsequent nodes. Connections between nodes represent the strength of influence between them. The strength of these connections is quantified by numerical values called weights. This network structure allows information to flow through the network, ultimately leading to a desired output.
Activation Functions
Activation functions introduce non-linearity into the network. Without these functions, a neural network would essentially be a linear model, unable to capture complex patterns in data. These functions introduce decision boundaries that allow the network to learn complex relationships between input and output. This allows the network to make more accurate predictions and generalize better to unseen data.
Weight Adjustment
The process of adjusting weights is crucial for learning. Initially, weights are assigned random values. As the network processes data, it compares its predictions to the actual output. Based on these discrepancies, the network adjusts the weights to reduce the difference between predicted and actual outputs. This iterative process of adjusting weights is a fundamental aspect of the learning process.
The adjustment process is often guided by optimization algorithms.
Backpropagation
Backpropagation is an algorithm used to train neural networks. It calculates the error between the predicted output and the desired output. Crucially, this error is then propagated backward through the network. The algorithm determines how much each weight needs to be adjusted to reduce the error. This iterative process allows the network to learn from its mistakes and improve its performance.
Backpropagation enables the network to refine its weights based on the error gradient.
Comparison of Activation Functions, Definition of neural network
| Activation Function | Formula | Characteristics | Suitable Use Cases |
|---|---|---|---|
| Sigmoid | σ(x) = 1 / (1 + e-x) | Output between 0 and 1, smooth, differentiable, good for binary classification. | Binary classification tasks, output needing values between 0 and 1. |
| ReLU (Rectified Linear Unit) | f(x) = max(0, x) | Simple, computationally efficient, avoids vanishing gradients. | Image recognition, natural language processing, and general-purpose tasks. |
| Tanh (Hyperbolic Tangent) | tanh(x) = (ex
|
Output between -1 and 1, zero-centered, can improve convergence compared to sigmoid. | Tasks where zero-centered output is beneficial, like in recurrent neural networks. |
This table provides a concise overview of common activation functions, highlighting their formulas, characteristics, and suitability for different tasks. Choosing the appropriate activation function is vital for optimizing network performance. For instance, ReLU’s simplicity makes it popular for its speed, while sigmoid’s bounded output is suitable for binary classification.
Learning and Training
Neural networks learn from data, adapting their internal connections to improve their performance on a specific task. This learning process is crucial for their ability to generalize and make accurate predictions on unseen data. Training involves presenting the network with examples, adjusting its weights based on the feedback, and iterating until satisfactory performance is achieved.The learning process in a neural network is analogous to a student learning from examples.
The network is presented with input data and the desired output, and through a process of trial and error, it adjusts its internal parameters to minimize the difference between its predicted output and the actual output. This process of adjustment is called backpropagation, and it’s a key component of supervised learning.
Data Usage in Training
Data is the lifeblood of neural network training. The quality and quantity of data directly impact the network’s ability to learn and generalize. Data sets are typically divided into training, validation, and testing sets to ensure the network doesn’t overfit to the training data. The training set is used to adjust the network’s parameters, the validation set is used to monitor the network’s performance during training, and the testing set is used to evaluate the network’s performance on unseen data.
Careful consideration of data pre-processing, including normalization and feature scaling, is essential for optimal training.
Supervised Learning
Supervised learning is a fundamental approach to training neural networks. In supervised learning, the network is trained on a dataset that includes both input data and corresponding target outputs. The network learns to map inputs to outputs by identifying patterns and relationships within the data. This approach is particularly effective when the desired output is known for each input example.
A neural network, essentially, is a complex system mimicking the human brain’s interconnected neurons. These networks process information in layers, learning from data to make predictions or classifications. Recent global market instability, like the tumble seen in global markets tumble trump tariffs china , highlights the need for sophisticated analytical tools, and neural networks are increasingly used to model and predict these complex economic shifts.
Ultimately, the definition of a neural network lies in its ability to learn and adapt, just as our understanding of the global economy is constantly evolving.
Examples of Supervised Learning Tasks
Numerous real-world tasks benefit from supervised learning in neural networks. Examples include:
- Image classification: Identifying objects (e.g., cats, dogs) in images.
- Spam detection: Distinguishing spam emails from legitimate emails.
- Medical diagnosis: Predicting the likelihood of a patient having a specific disease based on medical records.
- Natural language processing: Translating text between languages or generating summaries.
These examples showcase the diverse applications of supervised learning in neural networks, enabling the network to perform complex tasks by learning from labeled examples.
Learning Algorithms
Different learning algorithms are used to train neural networks, each with its own strengths and weaknesses. Choosing the appropriate algorithm depends on the specific task and the characteristics of the data.
| Algorithm | Characteristics |
|---|---|
| Stochastic Gradient Descent (SGD) | An iterative optimization algorithm that updates the network’s weights based on the error on a single training example at a time. Often used for its efficiency in large datasets. |
| Backpropagation | A crucial algorithm for training feedforward neural networks. It calculates the gradient of the loss function with respect to the network’s weights, allowing for efficient updates.
|
| Adam | An adaptive learning rate optimization algorithm that dynamically adjusts the learning rate for each weight based on the history of gradients. Often faster and more stable than SGD. |
| RMSprop | Another adaptive learning rate optimization algorithm that addresses the vanishing gradient problem in some cases. |
The table above highlights some common learning algorithms and their distinguishing features. Selecting the appropriate algorithm is critical for effective training and achieving desired results.
Applications and Use Cases

Neural networks are no longer a futuristic concept; they are deeply embedded in our daily lives, powering numerous technologies and processes. From recognizing faces in photos to predicting the likelihood of disease, neural networks are revolutionizing diverse fields. Their ability to learn from vast amounts of data and identify complex patterns makes them invaluable tools for solving intricate problems.
Real-World Applications
Neural networks are transforming various industries and aspects of modern life. Their versatility allows them to be applied in a wide range of tasks, from automating mundane tasks to tackling complex scientific challenges. Here are some compelling examples:
- Image Recognition: Neural networks excel at identifying objects, faces, and patterns in images, revolutionizing industries like medical imaging, self-driving cars, and security systems. For instance, they can detect cancerous cells in medical scans with a high degree of accuracy, significantly aiding in early diagnosis. Furthermore, they power facial recognition technology, enabling faster and more reliable identification.
- Natural Language Processing: Neural networks enable computers to understand, interpret, and generate human language. This translates into improved customer service chatbots, more accurate language translation services, and the ability to create human-like text.
- Medical Diagnosis: Neural networks are increasingly used in medical diagnosis, analyzing medical images, patient records, and other data to aid in the detection of diseases like cancer, heart conditions, and neurological disorders. These tools can help medical professionals make faster and more informed decisions, potentially leading to better patient outcomes.
- Financial Modeling: Neural networks are used to predict stock prices, assess risk, and detect fraudulent activities in financial markets. Their ability to identify complex patterns in financial data allows for more accurate and sophisticated models.
Image Recognition
Neural networks have significantly impacted image recognition, transforming how computers understand visual information. Convolutional Neural Networks (CNNs) are particularly effective at this task, leveraging their layered structure to identify complex patterns and features within images. The process involves feeding a large dataset of images to the network, allowing it to learn the characteristics of different objects and classify them accordingly.
Natural Language Processing
Neural networks are playing a crucial role in Natural Language Processing (NLP). Recurrent Neural Networks (RNNs) and Transformers are commonly used to analyze and generate human language. These networks are capable of understanding the context and meaning of words within sentences, leading to improved language translation, sentiment analysis, and chatbots that can communicate more naturally.
Medical Diagnosis
The applications of neural networks in medical diagnosis are vast and promising. They can analyze medical images like X-rays, MRIs, and CT scans to identify anomalies, patterns, and potential diseases. Neural networks can also process patient data, including medical history, symptoms, and test results, to predict the likelihood of various conditions. This can support faster and more accurate diagnoses, potentially saving lives.
Diverse Applications and Impact
| Application | Impact |
|---|---|
| Image Recognition (e.g., self-driving cars) | Enhanced safety and efficiency in transportation, improved accuracy in medical imaging |
| Natural Language Processing (e.g., chatbots) | Improved customer service, enhanced accessibility of information, automation of tasks |
| Medical Diagnosis (e.g., cancer detection) | Improved diagnostic accuracy, early detection of diseases, reduced mortality rates |
| Financial Modeling (e.g., fraud detection) | Increased security in financial transactions, reduced financial losses, improved investment strategies |
Architecture and Design
Neural networks, at their core, are intricate systems of interconnected nodes organized into layers. Understanding their architecture is crucial for effectively designing and training them for specific tasks. The arrangement of these layers, the connections between nodes, and the specific type of network dictate its capabilities and limitations. Different architectures excel at different types of problems, emphasizing different aspects of data processing.Different architectures allow for different types of information processing.
A feedforward network processes data in a single direction, while recurrent networks incorporate feedback loops to capture temporal dependencies, making them ideal for tasks like natural language processing or time series analysis. The choice of architecture is critical in achieving optimal performance and efficiency in a neural network.
Basic Feedforward Neural Network Architecture
Feedforward networks are the most common type, characterized by the unidirectional flow of information from input to output layers. They consist of interconnected layers of nodes, each layer performing a simple transformation on the data. Input data propagates forward through the network, layer by layer, until it reaches the output layer. No cycles or feedback connections exist.
Each node in a layer is connected to every node in the subsequent layer.
- Input Layer: This layer receives the initial data. For example, in image recognition, the input layer might represent pixel values.
- Hidden Layers: These intermediate layers perform complex transformations on the input data. The number of hidden layers and the number of nodes in each layer are crucial design parameters, impacting the network’s capacity to learn.
- Output Layer: This layer produces the final result. For example, in a classification task, the output layer might represent the probability of each class.
Recurrent Neural Network Structure
Recurrent neural networks (RNNs) are designed to handle sequential data, such as text or time series. Unlike feedforward networks, RNNs have feedback connections, allowing information to flow in loops. This allows them to maintain a state, remembering previous inputs to influence current outputs. This feature is vital for understanding context in sequential data.
- Recurrent Connections: These connections form loops within the network, enabling information to be passed between nodes in a sequence. This allows the network to retain information about previous inputs.
- Hidden State: Each node in a recurrent layer maintains a hidden state, which captures information from previous steps in the sequence. This state is updated with each new input, effectively storing context.
Neural Network Topologies
Different topologies are designed to handle specific types of data and tasks.
- Convolutional Neural Networks (CNNs): These networks excel at processing grid-like data, such as images. CNNs employ convolutional layers to extract features from the input data, which are then used for classification or other tasks.
- Long Short-Term Memory Networks (LSTMs): LSTMs are a type of RNN designed to address the vanishing gradient problem, enabling them to learn long-term dependencies in sequential data.
- Radial Basis Function Networks (RBFNs): These networks employ radial basis functions to map input data to output values. RBFNs are often used for function approximation and pattern recognition.
Visual Representation of a Neural Network
Imagine a network with three layers: input, hidden, and output. Nodes in each layer are connected to nodes in the subsequent layer by weighted connections. The input layer receives the data, the hidden layers process it, and the output layer produces the result. Weights on connections adjust during training, determining the strength of the signal passed between nodes.
Neural Network Architectures Table
| Type | Layers | Connectivity Patterns |
|---|---|---|
| Feedforward | Input, Hidden (multiple), Output | Single direction, no cycles |
| Recurrent | Input, Hidden (multiple), Output | Feedback connections, loops |
| Convolutional | Convolutional, Pooling, Fully Connected | Convolutional filters, pooling regions |
Data Representation
Neural networks require numerical data to learn patterns and make predictions. This numerical representation is crucial, as networks cannot directly process text, images, or other non-numerical forms. Therefore, transforming diverse data types into a standardized numerical format is a fundamental step in the process. The choice of representation significantly impacts the network’s performance and the insights it can extract.
Different Data Representation Methods
Various methods exist for transforming data into numerical representations suitable for neural networks. These include one-hot encoding, feature scaling, and embedding techniques. Each method has its strengths and weaknesses, making careful selection crucial for optimal network performance.
- One-Hot Encoding: This method converts categorical data into a binary vector. Each category is represented by a unique binary vector, with a ‘1’ in the position corresponding to the category and ‘0’ elsewhere. For example, if you have colors red, green, and blue, each color would be represented by a three-element vector: red = [1, 0, 0], green = [0, 1, 0], and blue = [0, 0, 1].
This approach is effective for representing discrete labels.
- Feature Scaling: This technique standardizes the range of numerical features. Common methods include min-max scaling, which scales features to a range between 0 and 1, and standardization, which centers features around zero with a unit variance. Feature scaling is important for preventing features with larger values from dominating the learning process.
- Embeddings: These are dense vector representations of discrete data like words or entities. Word embeddings, for example, capture semantic relationships between words. Word2Vec and GloVe are popular embedding techniques that map words to vectors in a high-dimensional space, where semantically similar words are located closer together. This allows networks to understand the context and relationships between data points.
Input Data Transformation
Input data, regardless of its original format, must be converted into a numerical representation suitable for neural networks. This process often involves several steps, depending on the nature of the data. For example, images are typically converted into pixel values, text is transformed into word embeddings, and audio signals are represented as time-series data.
Data Preprocessing Significance
Data preprocessing is an essential step before feeding data to a neural network. This step involves cleaning, transforming, and preparing the data to enhance the network’s learning process. Preprocessing steps often include handling missing values, removing outliers, and normalizing or standardizing the data. The goal is to improve the quality and consistency of the input data, ultimately leading to better model performance.
Data Normalization and Standardization
Data normalization and standardization are crucial preprocessing steps that aim to improve model performance. Normalization scales the data to a specific range, often between 0 and 1. Standardization, on the other hand, centers the data around zero with a unit variance. These techniques ensure that features with larger values do not disproportionately influence the learning process.
- Normalization: Normalization rescales the values of features to a specific range, usually between 0 and
1. The formula for min-max scaling is:(x – min(x)) / (max(x)
-min(x))where x is the original value and min(x) and max(x) are the minimum and maximum values of the feature, respectively.
- Standardization: Standardization transforms data to have a mean of zero and a standard deviation of one. The formula for standardization is:
(x – μ) / σ
where x is the original value, μ is the mean, and σ is the standard deviation of the feature.
Data Representation Methods Table
| Data Representation Method | Suitability for Neural Network Type | Example |
|---|---|---|
| One-hot encoding | Classification tasks with categorical labels | Representing colors (red, green, blue) |
| Feature scaling (min-max) | Networks sensitive to feature magnitude | Normalizing pixel values in an image |
| Feature scaling (standardization) | Networks sensitive to feature magnitude | Standardizing features in a dataset |
| Embeddings | Natural language processing tasks, recommendation systems | Representing words in a document |
Evaluation Metrics
Assessing the performance of a neural network is crucial for determining its effectiveness and suitability for a specific task. Different evaluation metrics provide insights into various aspects of the network’s predictions, enabling informed decisions about model selection and improvement. Choosing the appropriate metric depends heavily on the specific application and the desired outcome.
Neural networks, essentially, are complex systems designed to mimic the human brain’s learning process. Their ability to identify patterns and make predictions is quite remarkable. Recent news about the Italian Prime Minister Giorgia Meloni’s visit to the White House and her meeting with a person often referred to as Trump’s “whisperer” ( meloni white house visit trump whisperer ) raises interesting questions about how complex relationships between nations can be navigated.
Ultimately, these intricate networks, much like the political landscape, are fascinating to observe and understand. The definition of a neural network hinges on its ability to adapt and learn from data.
Common Evaluation Metrics
Evaluating a neural network’s performance requires carefully selecting metrics that align with the specific task. Common metrics include accuracy, precision, recall, F1-score, and area under the ROC curve (AUC). These metrics quantify different aspects of the network’s predictions, from overall correctness to its ability to identify specific classes. Understanding the nuances of each metric is vital for interpreting the results accurately.
Accuracy
Accuracy is a fundamental metric that measures the overall correctness of the network’s predictions. It represents the proportion of correctly classified instances out of the total instances. A high accuracy score suggests a well-performing network. However, accuracy alone may not be sufficient in scenarios with imbalanced datasets.
Precision and Recall
Precision and recall are crucial metrics, especially in scenarios with imbalanced datasets or when specific classes are of high importance. Precision measures the proportion of correctly predicted positive instances out of all predicted positive instances. Recall measures the proportion of correctly predicted positive instances out of all actual positive instances. In a medical diagnosis scenario, high precision means a low rate of false positives (diagnosing a healthy person as sick), while high recall means a low rate of false negatives (missing a sick person’s diagnosis).
Precision = True Positives / (True Positives + False Positives)Recall = True Positives / (True Positives + False Negatives)
F1-Score
The F1-score is a harmonic mean of precision and recall, providing a balanced measure of the network’s performance. It is particularly useful when precision and recall are equally important. A high F1-score indicates a good balance between both metrics.
Area Under the ROC Curve (AUC)
The AUC is a measure of the network’s ability to distinguish between different classes. It plots the true positive rate against the false positive rate at various thresholds. An AUC closer to 1 indicates a better ability to discriminate between classes.
Application Examples
Consider a spam detection system. High precision would be important to minimize unwanted emails reaching users’ inboxes, while high recall is needed to ensure that legitimate emails are not misclassified as spam. In medical diagnosis, high precision and recall are both crucial for accurately identifying diseases and avoiding both false positives and false negatives. For example, in cancer detection, a high recall ensures that most cancer cases are detected, while high precision reduces the rate of false alarms.
Evaluation Metrics Summary Table
| Metric | Description | Importance in Different Application Domains |
|---|---|---|
| Accuracy | Overall correctness of predictions | General classification tasks, balanced datasets |
| Precision | Proportion of correct positive predictions | Spam detection, medical diagnosis (minimizing false positives) |
| Recall | Proportion of correctly identified positive instances | Medical diagnosis (minimizing false negatives), fraud detection |
| F1-score | Balanced measure of precision and recall | Applications where both precision and recall are equally important |
| AUC | Measure of class separation | Classification problems with multiple classes, ranking tasks |
Advantages and Disadvantages
Neural networks have revolutionized various fields, from image recognition to natural language processing, due to their remarkable ability to learn complex patterns from data. However, like any powerful tool, they come with their own set of limitations. Understanding both the strengths and weaknesses is crucial for effectively deploying and interpreting neural network models.
Advantages of Neural Networks
Neural networks excel in tasks requiring pattern recognition and adaptation, making them highly effective in numerous applications. Their ability to learn complex relationships from data without explicit programming makes them particularly valuable for tasks where traditional algorithms struggle.
- Adaptability and Generalization: Neural networks can adapt to new data and generalize their learned patterns to unseen data, unlike traditional algorithms that often require significant re-tuning. This adaptability is crucial in dynamic environments where data distributions change over time.
- Complex Pattern Recognition: Neural networks are adept at identifying intricate patterns in data, surpassing traditional methods in areas like image recognition and natural language processing. Their hierarchical structure allows them to learn progressively more complex features.
- Robustness to Noise: Neural networks can handle noisy data, making them useful in real-world scenarios where data is not perfectly clean. This robustness is particularly important in applications like speech recognition and medical diagnosis.
Disadvantages of Neural Networks
Despite their advantages, neural networks also have limitations. Understanding these drawbacks is crucial for effective model development and deployment.
- Black Box Nature: Neural networks, especially deep ones, can be difficult to interpret, making it challenging to understand how they arrive at specific decisions. This “black box” nature can hinder trust and adoption in sensitive applications.
- Computational Cost: Training neural networks, particularly deep architectures, requires significant computational resources and time. This high computational cost can be prohibitive for resource-constrained environments.
- Overfitting and Generalization Issues: Neural networks can overfit to the training data, performing exceptionally well on the training set but poorly on unseen data. Careful regularization techniques are essential to prevent this issue.
Limitations in Specific Contexts
The effectiveness of neural networks can vary depending on the specific application. For instance, in situations with limited data, neural networks may struggle to generalize well.
- Limited Data: Neural networks require substantial amounts of training data to learn effectively. With limited data, overfitting becomes more likely, reducing the network’s ability to generalize to new, unseen instances.
- High Dimensionality: In high-dimensional datasets, the computational cost of training neural networks can be prohibitive, and feature selection becomes crucial.
- Interpretability Requirements: In contexts requiring transparency and interpretability, such as medical diagnosis or financial modeling, the black box nature of neural networks can be a significant limitation.
Comparison with Traditional Algorithms
Traditional algorithms, such as linear regression or decision trees, offer simplicity and interpretability. However, they often struggle with complex patterns found in real-world data.
| Feature | Neural Networks | Traditional Algorithms |
|---|---|---|
| Complexity | High | Low |
| Interpretability | Low | High |
| Computational Cost | High (training) | Low |
| Data Requirements | High | Variable |
| Pattern Recognition | Excellent | Limited (for complex patterns) |
Ending Remarks
In conclusion, understanding the definition of neural network opens a door to a vast field of possibilities. From the fundamental building blocks to their diverse applications, this overview provides a solid foundation for further exploration. Neural networks are more than just algorithms; they represent a powerful paradigm shift in how we approach complex problems and shape the future of technology.
Their continued development promises even more innovative applications in the years to come.