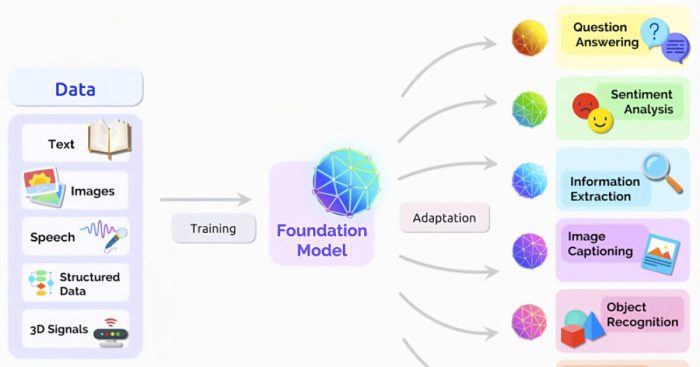
Definition of large language model llm – Definition of large language model (LLM): Understanding LLMs is key to grasping their potential and limitations. These sophisticated language models, unlike simpler systems, learn from massive datasets, allowing them to generate human-like text and engage in complex tasks. This exploration dives into the intricacies of LLM architecture, training methods, capabilities, and future trends.
LLMs are a fascinating area of study, and their potential to revolutionize various sectors is undeniable. From natural language processing to creative writing, the applications of LLMs are truly diverse. Understanding their core functionalities and limitations is crucial to harnessing their power responsibly and ethically.
Defining Large Language Models (LLMs)
Large language models (LLMs) are revolutionizing the way we interact with technology, enabling applications from chatbots to creative writing tools. They represent a significant advancement in artificial intelligence, demonstrating a remarkable ability to understand and generate human-like text. This capability stems from their unique architecture and training methods, which we will explore in detail.LLMs are not simply sophisticated text processing tools; they are complex systems that learn intricate patterns and relationships within vast datasets of text and code.
This learning process allows them to produce coherent and contextually relevant text, translate languages, and even answer questions with surprising accuracy. Crucially, their performance surpasses previous language models due to their massive scale and advanced training techniques.
Concise Definition of an LLM
A large language model (LLM) is a statistical model trained on a massive dataset of text and code. It learns patterns and relationships within the data, enabling it to generate human-like text, translate languages, and answer questions. This is accomplished through sophisticated neural network architectures.
Key Characteristics Distinguishing LLMs
LLMs differ from simpler language models through several key characteristics:
- Massive Datasets: LLMs are trained on significantly larger datasets of text and code compared to traditional language models. This allows them to learn a wider range of patterns and relationships.
- Complex Architectures: LLMs employ intricate neural network architectures, such as transformers, which enable them to process and understand context across long sequences of text. This contrasts sharply with simpler models that struggle with context.
- Advanced Training Techniques: LLMs are trained using advanced techniques like transfer learning and reinforcement learning, which improve their performance and capabilities.
- Contextual Understanding: LLMs excel at understanding the context of a text, allowing them to generate relevant and coherent responses in various situations. This is a marked improvement over previous models, which often lacked this ability.
Essential Components of an LLM Architecture
The architecture of an LLM typically involves several crucial components:
- Massive Dataset: A vast corpus of text and code is used for training. The quality and diversity of this data are critical for the model’s performance.
- Neural Network Architecture: A sophisticated neural network, such as a transformer, processes the input data and produces the output text. The architecture allows the model to capture long-range dependencies and context.
- Training Algorithm: Algorithms like backpropagation and stochastic gradient descent are used to adjust the model’s parameters during training, optimizing its performance on the given task.
- Hyperparameters: These settings control the training process, including the learning rate, batch size, and number of epochs. Proper tuning of hyperparameters is essential for achieving optimal results.
Categorization of LLMs
LLMs can be categorized based on their design and functionality.
- General-purpose LLMs: These models are trained on a broad range of text and code, enabling them to perform various tasks. Examples include GPT-3 and LaMDA.
- Specialized LLMs: These models are trained on specific datasets or for particular tasks, such as code generation or question answering. This approach often yields models with superior performance in their niche areas.
LLMs vs. Traditional Rule-Based Systems
Traditional rule-based systems for language processing rely on predefined rules and grammars. In contrast, LLMs learn patterns from data, enabling them to adapt to diverse contexts and generate more nuanced and contextually appropriate responses. LLMs surpass rule-based systems in handling ambiguity and complexity in language.
Key Differences Between LLM Architectures
| Architecture | Key Characteristics | Strengths | Weaknesses |
|---|---|---|---|
| Transformer-based | Employs attention mechanisms to capture relationships between words in a sequence. | Excellent contextual understanding, handles long sequences well. | Computationally expensive, requires large datasets. |
| Recurrent Neural Network (RNN)-based | Processes input sequentially, one word at a time. | Relatively simple to implement. | Struggles with long-range dependencies, context is less effectively captured. |
Training and Development of LLMs
Large language models (LLMs) are intricate systems, and their training and development require substantial resources and sophisticated methodologies. This process involves meticulously crafting the models, ensuring they learn effectively from vast datasets, and evaluating their performance against a range of criteria. Ethical considerations also play a crucial role in shaping the responsible development and deployment of these powerful tools.
Training Process of LLMs
The training process for LLMs involves feeding the model vast amounts of text data. This data is used to learn patterns, relationships, and structures within the language. The model iteratively adjusts its internal parameters, gradually improving its ability to generate coherent and contextually relevant text. This iterative refinement process is often computationally intensive, requiring substantial computing power and significant time investment.
Types of Data Used in Training LLMs
LLMs are trained on diverse textual data sources. These include books, articles, websites, code repositories, and even social media posts. The quality and quantity of the data significantly influence the model’s performance and capabilities. Data preprocessing steps, such as cleaning, tokenization, and normalization, are crucial for ensuring the data is suitable for training. Data augmentation techniques can further expand the dataset, thereby enhancing the model’s generalization ability.
Evaluation Methods for LLMs
Evaluating the performance of LLMs is a complex task. Various metrics are used to assess the model’s ability to generate coherent and relevant text. These metrics often focus on fluency, coherence, and accuracy. Human evaluation plays a crucial role in understanding how well the model performs in real-world scenarios. Benchmark datasets, specifically designed for evaluating LLM performance, are frequently used to compare different models and assess their strengths and weaknesses.
Challenges in Training and Developing LLMs
Several significant challenges hinder the efficient training and development of LLMs. Computational resources are a major hurdle, requiring immense processing power and memory to handle the vast datasets and complex models. Data quality and bias also pose significant concerns, as the models can perpetuate biases present in the training data. The sheer size and complexity of LLMs make them difficult to interpret and debug, potentially leading to unexpected outputs.
Furthermore, the development of robust and reliable evaluation methods remains an ongoing challenge.
Ethical Considerations in LLM Development
Ethical considerations are paramount in LLM development and deployment. The potential for LLMs to generate harmful or biased content necessitates careful consideration of their societal impact. Transparency and accountability are critical, as it’s crucial to understand how LLMs arrive at their outputs. Developing guidelines and frameworks for responsible use is essential to mitigate potential risks and ensure ethical deployment.
Comparison of Training Methodologies
| Methodology | Description | Advantages | Disadvantages |
|---|---|---|---|
| Fine-tuning | Pre-trained models are adapted to a specific task using a smaller dataset. | Faster training, leveraging pre-existing knowledge | Limited ability to learn complex tasks |
| Reinforcement Learning from Human Feedback (RLHF) | Models are trained to maximize human preferences through feedback. | Improved alignment with human values | Subjectivity in feedback, potential for bias |
| Self-Supervised Learning | Models learn from patterns in unlabeled data. | Reduced reliance on labeled data | Potentially weaker performance on specific tasks |
Capabilities and Limitations of LLMs
Large Language Models (LLMs) are rapidly evolving, showcasing remarkable capabilities in natural language processing. However, these powerful tools also have limitations, which need to be carefully considered when deploying them in real-world applications. Understanding both the strengths and weaknesses of LLMs is crucial for responsible development and effective utilization.
Core Capabilities in Natural Language Processing Tasks
LLMs excel at various natural language processing tasks due to their ability to understand and generate human-like text. These capabilities include:
- Text Summarization: LLMs can condense lengthy texts into concise summaries, preserving the core information. This is valuable for quickly understanding large volumes of data, like news articles or research papers.
- Translation: LLMs can translate text between different languages with increasing accuracy, bridging communication gaps and enabling global access to information.
- Question Answering: LLMs can answer a wide range of questions based on provided text, acting as a virtual knowledge repository. They are effective for retrieving specific information from large datasets.
- Text Generation: LLMs can create human-quality text for various purposes, such as writing articles, composing poems, or generating code snippets. This capability has implications for content creation and automation.
- Sentiment Analysis: LLMs can identify and categorize the emotional tone of text, helping businesses understand public opinion and customer feedback.
Limitations in Various Language Processing Tasks, Definition of large language model llm
Despite their impressive capabilities, LLMs face several limitations.
- Lack of Common Sense Reasoning: LLMs often struggle with tasks requiring common sense reasoning or understanding contextual nuances. They might generate plausible-sounding but illogical responses.
- Hallucinations: LLMs can fabricate information, producing outputs that seem accurate but are entirely fabricated. This “hallucination” problem can lead to misleading or inaccurate results.
- Bias and Discrimination: LLMs can perpetuate existing societal biases present in the training data. This can manifest in prejudiced language or unfair outcomes.
- Over-reliance on Patterns: LLMs primarily rely on patterns in the training data. They may struggle with novel or unusual inputs that deviate significantly from the patterns they’ve learned.
- Computational Costs: Training and running LLMs can be computationally expensive, requiring significant resources. This limits accessibility for smaller organizations or researchers.
Potential Biases in LLMs
The training data used to build LLMs can contain biases reflecting societal prejudices. These biases can be reflected in the output, leading to unfair or discriminatory outcomes.
- Gender Bias: LLMs may exhibit biases regarding gender roles and stereotypes, leading to outputs that reinforce harmful assumptions.
- Racial Bias: LLMs can perpetuate racial stereotypes, producing prejudiced language or outputs that perpetuate racial inequalities.
- Socioeconomic Bias: LLMs may reflect biases related to socioeconomic status, potentially leading to outputs that disadvantage certain groups.
Impact on Human Language Understanding
LLMs are transforming how humans interact with and understand language.
- Improved Accessibility: LLMs are making information more accessible by translating languages and summarizing complex texts.
- Enhanced Communication: LLMs can aid in communication by generating human-like text for various purposes, potentially bridging communication gaps.
- New Avenues for Learning: LLMs can personalize learning experiences by generating customized educational materials or providing instant answers to questions.
Examples of Successful Real-World Applications
LLMs are successfully tackling real-world problems in various domains.
- Customer Service Chatbots: LLMs power chatbots that provide efficient and accurate responses to customer inquiries, reducing wait times and improving satisfaction.
- Healthcare Diagnosis Support: LLMs can analyze medical records to identify potential patterns and support medical professionals in diagnosis and treatment decisions.
- Code Generation: LLMs can generate code snippets for software developers, increasing efficiency and reducing development time.
Strengths and Weaknesses of Different LLM Architectures
| LLM Architecture | Strengths | Weaknesses |
|---|---|---|
| Transformer-based | High accuracy in various tasks, capable of handling long sequences of text, adaptable to various applications. | Computationally expensive to train and run, susceptible to biases in training data. |
| Recurrent Neural Network (RNN)-based | Relatively simpler to implement, suitable for certain tasks like speech recognition. | Struggles with long-range dependencies in text, less accurate than transformer models. |
| Hybrid Architectures | Combine strengths of different architectures, potentially improving performance and efficiency. | More complex to develop and implement, may not always demonstrate significant improvements over simpler architectures. |
Applications and Impacts of LLMs
Large Language Models (LLMs) are rapidly transforming various sectors, from customer service to content creation. Their ability to understand and generate human-like text has opened up a world of possibilities, but also raises important considerations about their societal impact. This section delves into the diverse applications of LLMs, exploring their impact on industries and society as a whole.
Diverse Applications Across Sectors
LLMs are demonstrating remarkable versatility, finding applications in diverse sectors. Their capacity to process and understand vast amounts of text data enables them to perform tasks that were previously exclusive to human intelligence. This capability has significant implications for streamlining operations and enhancing efficiency in numerous industries.
Large language models (LLMs) are essentially sophisticated computer programs designed to process and generate human-like text. While these models are fascinating, the recent news about the Trump administration’s decision to block Medicare coverage for some anti-obesity drugs, as detailed in this article trump administration nixes anti obesity drugs medicare coverage , highlights a very different kind of powerful processing.
Ultimately, LLMs are a fascinating look into the potential and pitfalls of artificial intelligence, and these kinds of policy decisions have a real impact on how these technologies are developed and applied in the real world.
- Customer Service: LLMs can handle routine customer inquiries, providing instant support and resolving common issues. Chatbots powered by LLMs can offer 24/7 assistance, reducing wait times and improving customer satisfaction.
- Content Creation: LLMs can generate various types of content, including articles, summaries, scripts, and even poems. This capability can significantly reduce the time and effort required for content production, allowing businesses to create a broader range of content quickly and cost-effectively.
- Education: LLMs can personalize learning experiences, providing customized tutoring and support to students. They can also create interactive exercises and educational materials, enhancing the overall learning experience.
- Healthcare: LLMs can analyze medical records and research papers, aiding in diagnosis and treatment planning. They can also translate medical information and assist in drug discovery.
Transforming Industries
LLMs are revolutionizing numerous industries by automating tasks, improving decision-making, and fostering innovation. Their ability to process and interpret large datasets enables them to identify patterns and insights that might otherwise be missed by humans.
- Finance: LLMs can analyze financial data to identify investment opportunities, predict market trends, and detect fraudulent activities. This can lead to better investment decisions and more secure financial systems.
- Law: LLMs can analyze legal documents, summarize case law, and assist in legal research. This can significantly improve efficiency in legal processes and provide better access to legal information.
- Marketing: LLMs can generate targeted marketing campaigns, personalize customer experiences, and analyze customer feedback. This can lead to more effective marketing strategies and increased customer engagement.
Potential Societal Impacts
The societal impact of LLMs is multifaceted, encompassing both opportunities and challenges. Their widespread adoption has the potential to reshape industries and professions, necessitating adjustments in the workforce and societal structures.
- Job Displacement: The automation of tasks previously performed by humans raises concerns about job displacement. However, LLMs also create new job opportunities in areas such as training, maintenance, and oversight of the systems.
- Ethical Considerations: Bias in training data can lead to biased outputs from LLMs. Addressing these biases is crucial to ensure fairness and equity in the applications of these technologies.
- Misinformation and Manipulation: The ability of LLMs to generate realistic text and images raises concerns about the spread of misinformation and manipulation. Robust safeguards and regulations are needed to mitigate these risks.
Comparing LLM Use Across Industries
The applications of LLMs vary across industries, reflecting the unique needs and challenges of each sector. Finance, for example, utilizes LLMs for fraud detection and risk assessment, while healthcare leverages them for diagnosis and treatment support.
Large language models (LLMs) are essentially sophisticated computer programs designed to understand and generate human-like text. They’re trained on massive datasets of text and code, learning patterns and relationships between words. This knowledge helps them create new text, answer questions, and even translate languages. Research into how LLMs can help support individuals with neurodivergence, such as at the Pitt MEL Neurodivergence Autism ADHD initiative, the Pitt MEL neurodivergence autism ADHD , is fascinating and could lead to breakthroughs in accessibility and personalized learning.
Ultimately, LLMs are a powerful tool, and understanding their potential is key to harnessing their benefits.
| Industry | Primary Application | Impact |
|---|---|---|
| Finance | Fraud detection, risk assessment, algorithmic trading | Improved security, increased efficiency |
| Healthcare | Diagnosis support, treatment planning, drug discovery | Enhanced accuracy, personalized care |
| Customer Service | Automated responses, issue resolution | Reduced wait times, improved customer satisfaction |
Role in Creative Tasks
LLMs are increasingly used for creative tasks, such as writing poems, stories, and scripts. They can assist writers, artists, and musicians in generating ideas, exploring different styles, and experimenting with new forms of expression. They are not replacements for human creativity but tools to enhance and accelerate it.
Large language models (LLMs) are essentially sophisticated computer programs designed to understand and generate human-like text. They’re trained on massive datasets of text and code, enabling them to perform tasks like translation, summarization, and even creative writing. This technology is rapidly evolving, and its applications extend far beyond simple text processing. For example, check out how digital twins are revolutionizing remote work for blue-collar workers here.
Ultimately, LLMs are poised to reshape how we interact with information and technology in the future.
Future Trends in LLM Research: Definition Of Large Language Model Llm
The field of large language models (LLMs) is rapidly evolving, pushing the boundaries of artificial intelligence. Ongoing research is focused on improving their capabilities, addressing limitations, and exploring novel applications. The future of LLMs promises exciting advancements in human-computer interaction and technology in general. This exploration delves into the potential future directions of LLM research, including advancements in architecture, ethical considerations, and potential impacts on various sectors.
Advancements in LLM Architectures
Current LLM architectures, while impressive, have limitations. Future research will likely focus on developing more efficient and powerful models. This involves exploring alternative network structures, optimizing training processes, and potentially incorporating knowledge from other domains, such as scientific literature or specific industry data. The development of specialized LLMs for particular tasks, such as code generation or medical diagnosis, is also expected.
Enhanced Reasoning and Problem-Solving Capabilities
Current LLMs excel at text generation and translation but often struggle with complex reasoning and problem-solving tasks. Future research will likely focus on equipping LLMs with more sophisticated reasoning capabilities. This could involve integrating knowledge graphs, enabling LLMs to understand and manipulate relationships between concepts more effectively. Advanced techniques, like symbolic reasoning, may be integrated to enhance the models’ ability to tackle complex problems.
Examples of this are already emerging in specialized LLMs for tasks like mathematical theorem proving and logical reasoning.
Improved Understanding of Context and Nuance
LLMs often misinterpret context or struggle with subtle nuances in language. Future research will likely focus on improving their ability to understand and process context, including implicit meanings, emotions, and cultural references. This could involve training LLMs on massive datasets of diverse text types, incorporating sentiment analysis techniques, and potentially leveraging human feedback to refine their understanding of language.
The development of models that can effectively understand and respond to different linguistic styles and registers is a crucial aspect of this direction.
Addressing Ethical Concerns and Bias
The potential for LLMs to perpetuate or amplify biases present in their training data is a significant ethical concern. Future research will likely focus on developing techniques to mitigate bias in LLMs and ensure their fairness and ethical use. This may include methods for identifying and removing biased data from training sets, incorporating fairness metrics into the training process, and designing mechanisms for accountability and transparency.
A focus on responsible AI development will be essential to ensure these powerful tools are used for the benefit of society.
Potential for Enhanced Human-Computer Interaction
LLMs hold the potential to revolutionize human-computer interaction. Future LLMs are expected to be more intuitive and responsive, capable of understanding human intentions and preferences more effectively. This includes developing conversational interfaces that allow for natural and engaging interactions. Natural language processing is expected to drive more user-friendly and personalized experiences, making technology more accessible and intuitive.
Predicting Future Advancements in LLM Architectures
| Year | Advancement | Description |
|---|---|---|
| 2025 | Multi-modal LLMs | LLMs capable of processing and generating content across different modalities (text, images, audio). |
| 2028 | Federated Learning LLMs | LLMs trained on decentralized datasets, enhancing privacy and security. |
| 2030 | Explainable LLMs | LLMs with the ability to provide explanations for their outputs, fostering trust and understanding. |
| 2035 | LLMs with embodied intelligence | LLMs integrated with physical robots, enabling more complex and interactive tasks. |
Illustrative Examples and Use Cases

Large Language Models (LLMs) are rapidly transforming various industries, offering innovative solutions to complex problems. This section delves into practical applications, showcasing how LLMs can be implemented for specific tasks and the steps involved in building simple applications. From chatbots to content generation, LLMs are proving their versatility and potential.
A Chatbot for Customer Support
LLMs excel at mimicking human conversation. This example details a customer support chatbot built using a specific LLM. The chatbot is designed to handle common customer inquiries about product features, pricing, and troubleshooting.
- Data Preparation: A dataset of customer support interactions (emails, chat logs, FAQs) is compiled and cleaned. This dataset provides the training data for the LLM.
- Model Selection: A suitable LLM, potentially fine-tuned for conversational tasks, is chosen. Factors like response speed and accuracy are crucial considerations.
- Training and Fine-tuning: The selected LLM is trained on the prepared dataset. Fine-tuning allows for adaptation to the specific needs of the customer support domain.
- Integration and Deployment: The trained chatbot is integrated into the company’s website or customer support platform. APIs and SDKs facilitate this integration.
- Evaluation and Improvement: The chatbot’s performance is continuously monitored and evaluated based on user feedback and metrics like response time and accuracy. This iterative process allows for ongoing refinement of the chatbot’s capabilities.
Building a Simple Application
This section Artikels the steps involved in constructing a basic application leveraging an LLM.
- Define the Task: Clearly articulate the function of the application. For instance, a summarizing tool for lengthy documents.
- Data Collection: Gather relevant data to train the LLM. This could include articles, news stories, or other textual content.
- LLM Selection: Choose an appropriate LLM based on the complexity of the task and available resources.
- Integration: Integrate the selected LLM into the application’s codebase. This might involve using APIs or SDKs.
- Testing and Evaluation: Thoroughly test the application with various inputs and evaluate its performance against predefined criteria. Adjust the model or parameters as needed.
LLM-Powered Chatbot Interaction
The following example demonstrates a simplified interaction between a user and an LLM-powered chatbot:
User: “I’m having trouble connecting to my Wi-Fi.”
Chatbot: “I understand. To troubleshoot the connection, please try the following steps: check your router’s connection, ensure your device is within range, and verify the password.”
User: “Thanks. The password was incorrect.”
Chatbot: “Okay. Please re-enter the correct password. If the issue persists, please contact customer support.”
Technical Specifications for a Hypothetical LLM Project
| Component | Description |
|---|---|
| LLM | A large language model, potentially GPT-3.5-turbo, trained on a vast dataset of text and code. |
| Dataset | A corpus of product manuals, FAQs, and customer interactions, totaling 10 million tokens. |
| API | A cloud-based API for accessing the LLM’s functionalities. |
| Programming Language | Python, utilizing libraries like Transformers for model interaction. |
| Hardware | A cloud-based server with sufficient processing power to handle the LLM’s computations. |
Conclusion
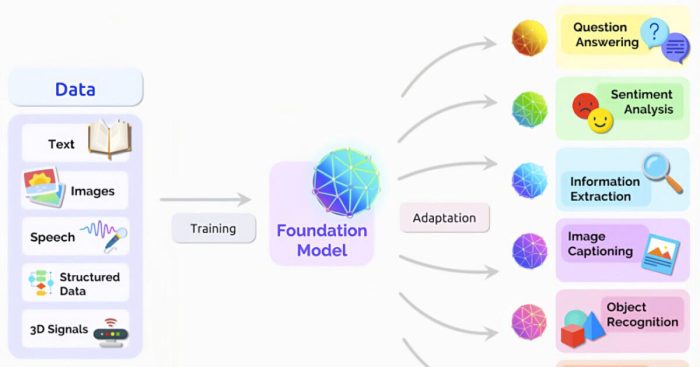
In conclusion, large language models are rapidly evolving, presenting both remarkable capabilities and inherent limitations. Their diverse applications across various sectors underscore their transformative potential, while ethical considerations and ongoing research are crucial for responsible deployment. The future of LLMs promises further innovation, shaping the way we interact with technology and each other.