Definition of deep learning lays the groundwork for a fascinating exploration of this rapidly evolving field. Deep learning, a subset of machine learning, uses artificial neural networks with multiple layers to analyze complex data and extract meaningful insights. This approach allows computers to learn from data without explicit programming, mimicking the human brain’s ability to identify patterns and make predictions.
From its historical roots in artificial neural networks to its current applications in image recognition, natural language processing, and healthcare, deep learning is transforming various industries. This exploration will delve into the core components of deep learning models, including neural network types, activation functions, and the crucial role of data handling and model training. We’ll also touch upon ethical considerations and the exciting future of this transformative technology.
Introduction to Deep Learning: Definition Of Deep Learning
Deep learning, a subset of machine learning, is revolutionizing various fields by enabling computers to learn from vast amounts of data without explicit programming. It mimics the structure and function of the human brain, using interconnected layers of artificial neurons to identify complex patterns and make predictions. This approach has led to remarkable advancements in image recognition, natural language processing, and other domains.Deep learning works by employing artificial neural networks with multiple layers.
These networks learn complex patterns and relationships within data by adjusting the connections between these layers. The more data the network is exposed to, the more accurate and sophisticated its predictions become.
Core Concepts of Deep Learning
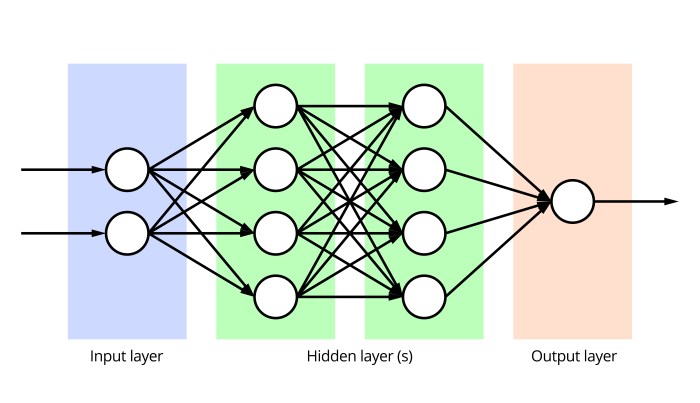
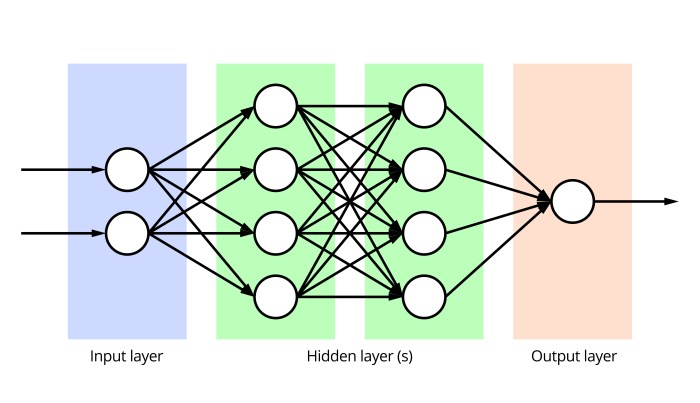
Deep learning relies on artificial neural networks, which are inspired by the biological neural networks in the human brain. These networks consist of interconnected nodes (neurons) organized in layers. The input layer receives data, while the output layer produces the results. Hidden layers in between process the information and extract increasingly complex features.
Historical Context and Development
The foundations of deep learning were laid in the 1940s and 1950s with the development of perceptrons, the simplest form of artificial neural networks. However, early attempts faced limitations due to computational power and data availability. The field experienced a resurgence in the 2010s with the advent of powerful GPUs and the availability of massive datasets, enabling training of deep neural networks with many layers.
Evolution of Deep Learning Architectures
Deep learning architectures have evolved significantly over time. Early architectures like Multilayer Perceptrons (MLPs) were relatively simple. Later, Convolutional Neural Networks (CNNs) emerged, excelling in image recognition tasks due to their ability to learn hierarchical spatial features. Recurrent Neural Networks (RNNs) were developed for sequential data like text and time series, enabling tasks like language translation and speech recognition.
More recently, architectures like Transformers have demonstrated superior performance in tasks involving complex relationships in data, particularly in natural language processing.
A Simple Analogy
Imagine a child learning to identify different fruits. A shallow learning approach might involve explicitly defining rules: “round and red = apple,” “long and green = banana.” Deep learning, however, is like the child observing many examples of apples and bananas. The child gradually learns to recognize patterns—shape, color, texture—and eventually accurately classify new fruits without explicit rules.
Each layer of the network learns progressively more complex features, ultimately enabling accurate fruit identification.
Examples of Deep Learning Applications
Deep learning has widespread applications across various industries. In healthcare, it is used for disease diagnosis and drug discovery. In finance, it is employed for fraud detection and algorithmic trading. In customer service, it powers chatbots and personalized recommendations. For example, self-driving cars utilize deep learning for object recognition and navigation.
Facial recognition software is another popular application, relying on deep learning models to identify individuals from images.
Key Components of Deep Learning Models

Deep learning models, at their core, are intricate networks of interconnected nodes, often called neurons. These networks learn complex patterns and relationships from data through a process of adjusting their internal parameters. Understanding the fundamental components of these models is crucial to comprehending their functionality and capabilities. This section delves into the key building blocks, including different types of neural networks, activation functions, weights and biases, and the critical role of layers.Deep learning models’ strength lies in their ability to automatically extract hierarchical features from raw data.
This automated feature extraction is made possible by the interplay of these key components. Each component plays a specific role in the learning process, contributing to the model’s overall performance.
Types of Neural Networks
Neural networks come in various architectures, each tailored for different tasks. Understanding these different architectures is essential for choosing the right model for a specific problem.
- Multilayer Perceptrons (MLPs): MLPs are fundamental feedforward networks. They consist of interconnected layers of neurons, with information flowing in a single direction from input to output. A simple example would be predicting whether an image contains a cat or a dog based on pixel data.
- Convolutional Neural Networks (CNNs): CNNs excel at processing grid-like data, such as images and videos. They employ convolutional layers to extract local features from the input data, making them highly effective in image recognition and object detection tasks. For instance, they are used in self-driving cars for identifying road signs and objects.
- Recurrent Neural Networks (RNNs): RNNs are designed for sequential data, such as text or time series. They have recurrent connections that allow information to persist through the network, making them ideal for tasks like language translation, speech recognition, and time-series prediction. For example, an RNN could be trained to predict the next word in a sentence given the preceding words.
- Long Short-Term Memory (LSTM) Networks: LSTMs are a specialized type of RNN designed to address the vanishing gradient problem in standard RNNs. This allows LSTMs to retain information over longer sequences, making them effective for tasks like machine translation and natural language processing where long-range dependencies are crucial. A good example would be understanding complex sentences with multiple clauses.
Activation Functions
Activation functions introduce non-linearity into the network, enabling the model to learn complex patterns and relationships in the data. Without them, the network would essentially be a linear model.
Deep learning, essentially, is a type of artificial intelligence that allows computers to learn from massive amounts of data. It’s like teaching a computer to recognize patterns, much like a human learning to identify a specific type of bird. For example, the recent public interest in President Donald Trump’s health, including his physical results and medical records, president donald trump health physical results medical records , might be viewed as an application of deep learning in a medical context, if one were to imagine the algorithms learning from various health data.
Understanding deep learning is crucial to appreciating its potential applications across various fields.
- Sigmoid: The sigmoid function maps any input value to a value between 0 and 1. It’s often used in binary classification tasks. For example, in predicting if an email is spam or not.
- ReLU (Rectified Linear Unit): The ReLU function outputs the input if it’s positive and zero otherwise. Its simplicity and efficiency make it a popular choice in many deep learning applications. For instance, it’s frequently used in image recognition models.
- Tanh (Hyperbolic Tangent): The tanh function maps any input value to a value between -1 and 1. It’s often used when the input values have a wider range of possibilities. An example could be in predicting stock prices.
Weights and Biases
Weights and biases are crucial parameters within a neural network that are adjusted during the training process to optimize the model’s performance.
Weights determine the strength of connections between neurons, and biases introduce a threshold for activation.
Weights are learned by adjusting the connections between neurons. Biases shift the activation threshold. The model adjusts these values to improve accuracy in its predictions.
Layers
Layers are the fundamental building blocks of deep learning architectures. They perform specific operations on the data flowing through the network.
- Input Layer: Receives the initial data. This is the first layer in the network.
- Hidden Layers: Process the data and extract features. These layers are situated between the input and output layers.
- Output Layer: Produces the final result. This layer provides the model’s prediction or classification.
Comparison of Neural Network Types
| Neural Network Type | Data Type | Typical Applications |
|---|---|---|
| MLP | Various | Classification, Regression |
| CNN | Grid-like (images, videos) | Image recognition, object detection |
| RNN | Sequential (text, time series) | Natural language processing, time series prediction |
| LSTM | Sequential (text, time series) | Natural language processing, time series prediction (with long-range dependencies) |
Deep Learning Applications
Deep learning, with its ability to learn complex patterns from vast amounts of data, has revolutionized numerous fields. Its applications span diverse domains, from image recognition and natural language processing to healthcare and beyond. This section delves into the practical uses of deep learning, highlighting its impact on various industries.
Real-World Applications
Deep learning is no longer a theoretical concept; it’s actively shaping the world around us. From personalized recommendations on streaming services to autonomous vehicles navigating complex environments, deep learning algorithms are at work. These algorithms can identify subtle patterns and relationships in data, leading to breakthroughs in areas previously considered impossible.
Image Recognition
Deep learning excels at image recognition tasks. Convolutional Neural Networks (CNNs) are specifically designed to process visual information, enabling powerful image analysis capabilities. These networks can identify objects, faces, and even emotions in images with remarkable accuracy. For example, CNNs are crucial for medical image analysis, allowing for early detection of diseases like cancer.
Natural Language Processing (NLP)
Deep learning is transforming natural language processing, enabling computers to understand and process human language. Recurrent Neural Networks (RNNs) and Transformers are key components in tasks like machine translation, sentiment analysis, and chatbots. These models can learn the nuances of language, allowing them to generate human-quality text and understand complex sentences. For example, Google Translate utilizes deep learning to provide accurate and contextually relevant translations.
Healthcare Applications
Deep learning is rapidly transforming healthcare, offering new possibilities for diagnosis, treatment, and drug discovery. Deep learning models can analyze medical images (X-rays, MRIs, etc.) to detect anomalies and assist in diagnosis. Furthermore, they can analyze patient records to identify patterns and predict potential health risks. For instance, deep learning algorithms can identify cancerous cells in pathology images with high accuracy.
Table of Deep Learning Applications
| Application Area | Specific Use Cases |
|---|---|
| Image Recognition | Object detection in satellite imagery, facial recognition, medical image analysis (e.g., detecting tumors in mammograms), autonomous driving |
| Natural Language Processing | Machine translation, sentiment analysis (e.g., analyzing customer reviews), chatbot development, text summarization, question answering systems |
| Healthcare | Disease diagnosis (e.g., identifying diabetic retinopathy from retinal images), drug discovery, personalized medicine, predicting patient outcomes |
| Finance | Fraud detection, risk assessment, algorithmic trading, customer churn prediction |
| Retail | Product recommendations, inventory management, customer segmentation, personalized marketing |
Data Handling and Deep Learning
Deep learning models thrive on data. However, raw data isn’t always ready for use. Transforming and preparing the data is often a crucial step in achieving optimal model performance. This process, known as data preprocessing, involves cleaning, augmenting, and structuring the data to ensure it’s suitable for the deep learning algorithms. Proper data handling is as important as the model architecture itself.
Significance of Data Preprocessing
Data preprocessing is vital for deep learning models because raw data often contains inconsistencies, missing values, and irrelevant features. These imperfections can negatively impact the model’s training and generalization capabilities. Data preprocessing addresses these issues by cleaning the data, converting it into a suitable format, and augmenting it to increase the dataset’s size and variety. This, in turn, leads to a more robust and accurate model.
Common Techniques for Data Cleaning and Preparation
Data cleaning and preparation involve several techniques to ensure data quality. These techniques include handling missing values (e.g., imputation with mean or median), removing outliers (e.g., using statistical methods), and transforming data types (e.g., converting categorical variables into numerical representations). Furthermore, standardizing or normalizing features can prevent features with larger values from dominating the model.
- Handling Missing Values: Missing data points can significantly impact model training. Strategies include removing rows with missing values, imputing missing values using the mean or median of the feature, or using more sophisticated methods like K-Nearest Neighbors imputation. The best approach depends on the nature of the missing data and the size of the dataset.
- Outlier Removal: Outliers, or data points that deviate significantly from the rest of the data, can skew the model’s learning process. Methods for identifying and handling outliers include statistical methods like the Z-score or IQR (interquartile range) and visual inspection using box plots or scatter plots. Removal is sometimes not necessary; sometimes, outliers can be valuable.
- Feature Scaling: Feature scaling ensures that features with larger values do not unduly influence the model. Methods include standardization (to zero mean and unit variance) and normalization (to a specific range, like 0-1). This helps the model to learn more effectively from the data.
Data Augmentation in Deep Learning
Data augmentation techniques artificially increase the size and variety of the training dataset. This is particularly beneficial when dealing with limited data. Augmentation methods include image transformations (rotation, flipping, cropping), text transformations (synonyms, paraphrasing), and more.
- Image Augmentation: Common image augmentation techniques include rotations, flips, zooms, and color jitters. These transformations do not change the underlying meaning of the image but introduce variations to the training data, which helps the model generalize better.
- Text Augmentation: In text data, augmentation involves techniques like synonym replacement, back-translation, and random insertion/deletion of words. These methods help improve the model’s understanding of different wordings and contexts.
Importance of Data Quality in Deep Learning Models, Definition of deep learning
Data quality is paramount for building accurate and reliable deep learning models. Inaccurate, inconsistent, or incomplete data can lead to biased or unreliable models. High-quality data ensures the model learns from meaningful patterns and generalizes well to unseen data. Careful attention to data quality is crucial throughout the entire data pipeline.
Structuring a Data Pipeline for Deep Learning
A well-structured data pipeline is essential for efficient data handling in deep learning. The pipeline should include stages for data ingestion, preprocessing, augmentation, and validation. A clear and well-defined pipeline ensures data consistency and reliability throughout the process.
- Data Ingestion: This stage involves collecting data from various sources, such as databases, APIs, or file systems. Robust mechanisms for data ingestion are essential to ensure data quality and prevent inconsistencies.
- Preprocessing: This stage involves cleaning, transforming, and preparing the data as discussed earlier. This stage must be well-defined to ensure consistent data quality across the entire pipeline.
- Augmentation: This stage is focused on increasing the dataset’s size and diversity. The appropriate augmentation techniques must be chosen based on the nature of the data and the model.
- Validation: This stage involves assessing the quality of the preprocessed data and the effectiveness of the augmentation steps. Validation data should be held separate from training and testing data to evaluate the model’s performance on unseen data.
Training Deep Learning Models
Deep learning models, like sophisticated algorithms, require a careful training process to achieve desired performance. This involves feeding vast amounts of data to the model, allowing it to learn patterns and relationships. The process is iterative, with adjustments made to the model’s internal parameters based on the errors it makes during predictions. Understanding the nuances of this training process is crucial for building effective and reliable deep learning applications.The training process involves presenting the model with input data and comparing its predictions with the actual target values.
Based on the difference (loss), adjustments are made to the model’s internal parameters to reduce the error. This iterative process continues until the model reaches a satisfactory level of performance. Crucially, effective training depends on careful selection of optimization algorithms, loss functions, and model validation techniques.
Optimization Algorithms
Optimization algorithms are essential components of deep learning model training. They dictate how the model’s parameters are adjusted to minimize the loss function. Different algorithms have varying strengths and weaknesses, impacting training speed and the final model’s performance. Common optimization algorithms include stochastic gradient descent (SGD), Adam, and RMSprop. Each algorithm employs a different strategy for calculating and updating model parameters.
For example, Adam combines the advantages of both momentum and RMSprop, often proving effective for complex models and large datasets.
Loss Functions
Loss functions quantify the difference between the model’s predictions and the actual target values. Choosing an appropriate loss function is critical, as it directly influences the model’s learning process. Common loss functions include mean squared error (MSE) for regression tasks and categorical cross-entropy for classification tasks. Mean Squared Error (MSE) measures the average squared difference between predicted and actual values, while Categorical Cross-Entropy measures the difference between predicted and true probability distributions.
The choice depends on the nature of the problem and the desired outcome.
Model Validation
Model validation is a crucial step during training. It helps assess the model’s generalization ability, which is its ability to perform well on unseen data. Validation involves reserving a portion of the training data to evaluate the model’s performance during the training process. This prevents overfitting, where the model performs exceptionally well on the training data but poorly on new, unseen data.
Techniques like k-fold cross-validation are used to further refine the validation process and obtain more reliable estimates of the model’s performance. This is important because a model that performs well on training data might not perform as well on real-world data.
Training Process Flowchart
The flowchart below illustrates the complete deep learning model training process.“`+—————–+| Data Preparation |+—————–+| | || V |+—————–+| Model Definition |+—————–+| | || V |+—————–+| Model Training |+—————–+| | || V |+—————–+| Validation |+—————–+| | || V |+—————–+| Evaluation |+—————–+| | || V |+—————–+| Model Deployment|+—————–+“`
Ethical Considerations in Deep Learning
Deep learning models, while powerful, are not without their ethical pitfalls. Their reliance on vast datasets and complex algorithms can inadvertently perpetuate existing societal biases, leading to unfair or discriminatory outcomes. Understanding these potential issues and proactively addressing them is crucial for responsible development and deployment of these technologies. Building trust in deep learning systems requires a commitment to fairness, accountability, and explainability.The ethical implications of deep learning extend beyond the technical realm, impacting societal values and individual rights.
Developing responsible deep learning models requires a holistic approach that considers the potential for bias, fairness concerns, and the need for explainability. A deep understanding of these issues is essential to prevent unintended harm and ensure that these powerful tools are used for the benefit of all.
Deep learning, essentially, is a subset of machine learning focused on artificial neural networks. It’s all about complex algorithms mimicking the human brain to identify patterns and make predictions. This kind of technology has many applications, from image recognition to natural language processing. Interestingly, the way we process information, even in seemingly unrelated fields like health or politics, can be compared to deep learning.
For example, Robert F. Kennedy Jr.’s political commentary often involves complex analyses of various factors influencing public opinion, which in a way resembles the sophisticated pattern recognition that deep learning systems utilize. Ultimately, deep learning is about building systems that can learn from vast amounts of data and improve their performance over time.
Potential Biases in Deep Learning Models
Deep learning models learn from data, and if the data reflects existing societal biases, the model will likely perpetuate and even amplify them. For example, a facial recognition system trained predominantly on images of light-skinned individuals might perform poorly on images of people with darker skin tones, leading to misidentification. Similarly, a loan application model trained on historical data that reflects gender or racial biases could result in discriminatory lending practices.
These biases can stem from various sources, including historical data imbalances, skewed representation in training datasets, and even implicit biases in the data collection process.
Importance of Fairness and Accountability in Deep Learning Systems
Fairness and accountability are paramount in deep learning systems. Fairness ensures that the model treats all individuals and groups equitably, without discrimination. Accountability, on the other hand, provides a mechanism for understanding how the model arrives at its decisions and for rectifying any unfair outcomes. If a loan application model consistently denies loans to individuals from a specific demographic group, it’s essential to understand the underlying reasons and implement corrective measures to address the bias.
Challenges Related to Explainability in Deep Learning Models
Deep learning models, particularly complex neural networks, often operate as “black boxes,” making it difficult to understand how they arrive at specific predictions. This lack of explainability can hinder trust and accountability, especially in critical applications like medical diagnosis or criminal justice. Understanding the decision-making process of a model is essential for identifying and mitigating biases and for ensuring that its outputs are reliable and justifiable.
Deep learning, essentially, is a subset of machine learning that uses artificial neural networks to analyze complex data. While fascinating, its applications extend beyond just data analysis, and in fact, the potential of deep learning could be pivotal in unlocking the resources of the deep sea. For example, it could be employed in autonomous underwater vehicles (AUVs) to assess the feasibility and sustainability of deep sea mining operations, as detailed in this insightful article about how Trump could boost deep sea mining.
how trump could boost deep sea mining Ultimately, understanding deep learning’s capabilities is crucial to comprehending its impact on various fields, including resource management.
Responsibility of Developers When Building Deep Learning Models
Developers bear a significant responsibility in ensuring that their deep learning models are fair, accountable, and transparent. This includes carefully considering the data used for training, identifying potential biases, and implementing mitigation strategies. They should also strive to build models that are explainable, allowing for scrutiny and understanding of their decision-making processes. This responsibility extends beyond the technical aspects to encompass the ethical implications of their work.
Steps to Mitigate Potential Biases in Deep Learning Models
Several strategies can help mitigate biases in deep learning models. One key step is to ensure the dataset used for training is diverse and representative of the population the model will serve. This involves actively seeking out and incorporating data from underrepresented groups. Furthermore, employing techniques to detect and correct for bias in the training process can help reduce unfair outcomes.
Finally, developing models that are explainable allows for greater scrutiny and identification of potential biases.
- Data Collection and Preprocessing: Carefully curate a diverse and representative dataset. Address potential imbalances in the data distribution to avoid skewed results. Employ data cleaning and preprocessing techniques to remove noise and inconsistencies.
- Bias Detection Techniques: Implement methods to identify potential biases within the data and model outputs. Utilize fairness metrics and evaluation protocols to assess the model’s impact on different groups.
- Model Design and Training: Develop models that are robust and resistant to bias amplification. Use techniques such as adversarial training to enhance the model’s ability to generalize across different data points.
- Explainability Mechanisms: Incorporate explainable AI (XAI) techniques to understand how the model arrives at its predictions. This allows for a deeper understanding of the model’s decision-making process and facilitates the identification of potential biases.
Future of Deep Learning
The field of deep learning is rapidly evolving, with new advancements and applications emerging constantly. This dynamic nature presents both exciting opportunities and challenges. From pushing the boundaries of artificial intelligence to transforming industries, the future of deep learning is brimming with potential. Understanding these trends and the associated implications is crucial for anyone interested in this exciting field.
Predictions for Future Advancements
Deep learning models are constantly being refined to improve accuracy, efficiency, and generalizability. Expect to see further development in areas like model compression and acceleration, enabling deployment on resource-constrained devices. Increased focus on explainable AI (XAI) will also be crucial to building trust and understanding in deep learning systems.
Emerging Trends
Several trends are shaping the future of deep learning. Federated learning, a distributed training approach, is gaining traction, allowing models to be trained on decentralized datasets without compromising privacy. Self-supervised learning, a technique that learns from unlabeled data, is another emerging trend, promising to unlock the potential of vast amounts of untapped data. Furthermore, the integration of deep learning with other fields, like robotics and computer vision, will lead to more sophisticated and practical applications.
Open Problems and Research Areas
Despite the progress, significant challenges remain in deep learning. Developing robust and generalizable models for diverse and complex tasks is crucial. Ensuring fairness and mitigating biases in deep learning algorithms is another important research area. Finally, understanding the limitations and potential vulnerabilities of deep learning models is essential for responsible development and deployment.
Impact on Various Industries
Deep learning’s potential impact spans across various sectors. In healthcare, deep learning can revolutionize diagnostics, drug discovery, and personalized medicine. In finance, it can improve fraud detection, risk assessment, and algorithmic trading. The retail industry can leverage deep learning for personalized recommendations, inventory management, and customer service. Manufacturing processes can benefit from optimized production planning, quality control, and predictive maintenance, thanks to deep learning.
Overall, the practical applications of deep learning will reshape numerous industries, offering significant improvements in efficiency, accuracy, and decision-making.
A Vision for the Future
Deep learning will continue to be a driving force in the advancement of artificial intelligence. It will seamlessly integrate into diverse industries, automating tasks, improving decision-making, and unlocking unprecedented levels of efficiency and accuracy. The future promises a world where deep learning empowers us to address complex challenges and unlock opportunities previously unimaginable. With responsible development and ethical considerations at the forefront, deep learning can pave the way for a more intelligent and prosperous future.
Final Conclusion
In conclusion, deep learning’s ability to extract insights from vast amounts of data, coupled with its versatility across numerous applications, is revolutionizing how we approach problem-solving in diverse fields. Understanding its principles, from model architecture to ethical implications, is crucial for anyone seeking to navigate the evolving landscape of artificial intelligence. The future of deep learning holds immense promise, and continuous learning and adaptation will be key to unlocking its full potential.