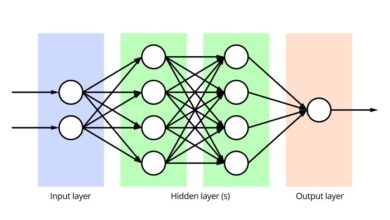
Definition of data mining: Uncovering hidden patterns and insights within vast datasets is the core of data mining. Imagine having a treasure chest filled with valuable information, but the key to unlocking it is hidden within the data itself. Data mining unearths those keys, transforming raw data into actionable knowledge. This exploration delves into the historical context, core concepts, techniques, applications, and the essential process of evaluating and utilizing the mined information.
Data mining is a powerful process, encompassing a range of techniques from simple statistical analysis to complex machine learning algorithms. It involves identifying patterns, trends, and anomalies in data to extract meaningful insights. This knowledge can then be used to make predictions, improve decision-making, and drive innovation across various industries. From healthcare to finance, marketing, and scientific research, data mining has revolutionized the way we understand and utilize information.
Introduction to Data Mining

Data mining is the process of discovering patterns, trends, and insights from large datasets. It involves using various techniques to extract knowledge from raw data, transforming it into actionable information that can be used to make informed decisions. This process is crucial in today’s data-driven world, enabling businesses and organizations to gain a competitive edge by understanding their customers, optimizing operations, and identifying new opportunities.Data mining builds upon the foundation of databases and statistical analysis, leveraging computational power to uncover hidden relationships and patterns within complex data.
The ultimate goal is to transform raw data into valuable knowledge, facilitating improved decision-making across diverse industries.
Definition of Data Mining
Data mining is the non-trivial extraction of implicit, previously unknown, and potentially useful patterns from data. This process encompasses various techniques, from simple statistical analyses to sophisticated machine learning algorithms, aimed at identifying meaningful relationships and insights within large datasets. Data mining distinguishes itself from traditional database systems by focusing on knowledge discovery rather than just data storage and retrieval.
Historical Context of Data Mining
The roots of data mining lie in the evolution of database management systems and statistical methods. Early database systems primarily focused on data storage and retrieval. As data volumes grew, the need for extracting meaningful insights emerged, paving the way for the development of data mining techniques. The increasing computational power and availability of large datasets further fueled the growth of this field, allowing researchers and practitioners to uncover intricate patterns and relationships within vast amounts of information.
Relationship with Other Fields
Data mining is closely intertwined with other fields, notably database management and statistics. Data mining relies on efficient database management systems for storing, retrieving, and manipulating large datasets. Statistical methods provide the theoretical framework for analyzing the data and identifying patterns. The synergy between these disciplines allows data mining to extract actionable knowledge from vast quantities of data.
Applications in Various Industries
Data mining has a wide range of applications across numerous industries. In finance, it’s used for fraud detection and risk assessment. In marketing, it’s used for customer segmentation and targeted advertising. In healthcare, it’s used for disease prediction and personalized medicine. In retail, it’s used for inventory management and sales forecasting.
These are just a few examples; data mining is proving valuable in virtually every sector where large datasets are available.
Types of Data Mining Tasks
Data mining encompasses a variety of tasks, each designed to extract different types of knowledge from data. These tasks often utilize different techniques and algorithms.
| Task Type | Description |
|---|---|
| Classification | Predicting the class or category to which a data point belongs based on its features. For example, classifying emails as spam or not spam. |
| Clustering | Grouping similar data points together based on their characteristics. For instance, segmenting customers based on purchasing behavior. |
| Association Rule Mining | Discovering relationships between different items in a dataset. An example is finding items frequently purchased together in a supermarket. |
| Regression | Predicting a continuous value based on the values of other variables. Predicting house prices based on size, location, and other factors. |
| Sequential Pattern Mining | Identifying sequences of events that occur frequently in a dataset. For instance, analyzing customer purchase history to identify trends in buying patterns. |
Core Concepts in Data Mining
Data mining is more than just sifting through mountains of data; it’s about extracting meaningful insights and patterns to solve problems and make informed decisions. This process relies on a robust understanding of core concepts, including data preprocessing, visualization, algorithm selection, and ethical considerations. Mastering these elements is crucial for successful data mining projects, enabling organizations to unlock the hidden potential within their data.
Data Preprocessing
Data preprocessing is a crucial initial step in any data mining project. Raw data is often incomplete, inconsistent, noisy, and irrelevant. Preprocessing techniques aim to transform this raw data into a clean, consistent, and usable format. These techniques improve the quality and reliability of the data, directly impacting the accuracy and efficiency of subsequent analysis. Common preprocessing steps include handling missing values, smoothing noisy data, converting data types, and selecting relevant features.
Data Visualization Techniques, Definition of data mining
Effective data visualization plays a vital role in data mining. Visual representations of data allow analysts to quickly identify patterns, trends, and outliers that might be missed in raw data. Visualizations enable a more intuitive understanding of the data, facilitating better interpretation and decision-making. Techniques such as scatter plots, histograms, box plots, and heatmaps are frequently used to reveal insights and support data-driven conclusions.
For instance, a scatter plot can reveal correlations between variables, while a histogram can illustrate the distribution of a single variable.
Data Mining Algorithms
A wide array of data mining algorithms exist, each designed for specific tasks and data types. These algorithms employ different techniques to discover patterns and relationships in the data. Classification algorithms predict categorical outcomes, such as predicting whether a customer will churn or not. Regression algorithms model relationships between variables, such as predicting house prices based on size and location.
Clustering algorithms group similar data points together, such as segmenting customers based on their purchasing behavior. Association rule mining identifies relationships between different items, like finding items frequently purchased together in a supermarket.
Factors Affecting Algorithm Performance
Several factors significantly influence the performance of data mining algorithms. These factors include the quality of the data, the choice of algorithm, the size of the dataset, the computational resources available, and the presence of outliers. High-quality data, appropriate algorithms, and adequate computational resources are paramount to obtaining accurate and reliable results. The presence of outliers can skew results and require careful handling.
Ethical Considerations and Challenges
Data mining, while powerful, presents ethical considerations and challenges. Issues such as privacy concerns, data security, bias in algorithms, and potential misuse of insights must be addressed. Ensuring data privacy and obtaining informed consent from data subjects are crucial. Data mining algorithms must be carefully designed to avoid bias and discrimination. The potential for misuse of data insights requires responsible development and deployment of data mining systems.
Data mining, basically, is about finding patterns in large datasets. It’s a powerful tool, and you can see how it might be applied in a complex case like the Mahmoud Khalil case, involving Trump’s immigration policies, student activism, and potential deportations, as discussed in this article. Analyzing the data surrounding such a situation could reveal important insights into public opinion and political movements, ultimately highlighting the value of data mining techniques in understanding complex social phenomena.
Steps in a Typical Data Mining Project
| Step | Description |
|---|---|
| Data Collection | Gathering relevant data from various sources. |
| Data Preprocessing | Cleaning, transforming, and preparing the data for analysis. |
| Data Exploration | Analyzing and visualizing the data to identify patterns and trends. |
| Model Building | Developing and selecting appropriate data mining algorithms. |
| Model Evaluation | Assessing the performance of the chosen model. |
| Deployment and Monitoring | Implementing the model for practical use and continuously monitoring its performance. |
Techniques and Methods in Data Mining
Data mining is a powerful tool for extracting valuable insights from vast datasets. It relies on a diverse range of techniques, ranging from statistical modeling to sophisticated machine learning algorithms. Understanding these methods is crucial for effectively applying data mining to solve real-world problems and gain a competitive edge. This section delves into the core techniques and methods used in data mining, demonstrating their practical applications and emphasizing the crucial role of data structures and tools in the process.Effective data mining hinges on selecting the appropriate techniques to address specific objectives.
Whether identifying patterns in customer behavior, predicting future trends, or uncovering anomalies in financial data, the correct application of statistical methods and machine learning algorithms are paramount. Data structures also play a significant role in the efficiency and accuracy of data mining processes.
Statistical Methods in Data Mining
Statistical methods are fundamental in data mining, providing tools for summarizing data, identifying relationships, and testing hypotheses. Techniques like regression analysis, hypothesis testing, and correlation analysis are frequently used to uncover patterns and trends within datasets. For example, regression analysis can model the relationship between variables, allowing for predictions based on observed data. This is particularly useful in business contexts for forecasting sales, customer churn, or product demand.
Machine Learning Algorithms in Data Mining
Machine learning algorithms play a critical role in data mining, enabling the discovery of patterns and insights in complex datasets. Supervised learning algorithms, like decision trees, support vector machines, and neural networks, learn from labeled data to predict outcomes. Unsupervised learning algorithms, such as clustering algorithms, identify hidden patterns and structures in unlabeled data.
- Decision Trees: These algorithms use a tree-like structure to model decisions and their possible outcomes. They are often used for classification tasks, such as identifying fraudulent transactions or categorizing customer segments.
- Support Vector Machines (SVMs): SVMs find optimal hyperplanes to separate data points into different classes. They are effective in high-dimensional spaces and are used in various applications, including image recognition and text classification.
- Neural Networks: These algorithms are inspired by the structure of the human brain. They consist of interconnected nodes (neurons) that process information and learn complex patterns. They are powerful for tasks like image recognition, natural language processing, and prediction modeling.
Data Structures in Data Mining
Efficient data management is crucial for data mining. Different data structures cater to various data mining needs.
- Relational Databases: These databases organize data into tables with rows and columns, facilitating structured queries and data retrieval. They are widely used in data mining for storing and accessing transactional data.
- Data Warehouses: These are specialized databases designed for analytical processing. They integrate data from various sources, providing a comprehensive view of business operations. Data warehouses are critical for data mining, providing a consolidated repository of historical data for trend analysis and business intelligence.
Data Mining and Business Intelligence
Data mining is an integral part of business intelligence, providing insights that drive strategic decision-making. By analyzing historical data, businesses can identify trends, predict future outcomes, and tailor their strategies accordingly. For example, a retail company can use data mining to understand customer purchasing patterns, personalize marketing campaigns, and optimize inventory management.
Supervised vs. Unsupervised Learning
Supervised learning algorithms require labeled data, enabling them to learn from examples and make predictions. Unsupervised learning algorithms, on the other hand, discover hidden patterns and structures in unlabeled data. The choice between supervised and unsupervised learning depends on the specific objectives and the availability of labeled data.
Data mining, in simple terms, is about finding hidden patterns in large datasets. It’s like sifting through a mountain of information to uncover meaningful insights. Thinking about it in the context of the Netflix series “The Gardener,” the show’s ending, as discussed in this article about the gardener netflix ending , highlights how data mining could be used to understand the characters’ motivations and relationships.
Ultimately, the core idea behind data mining remains the same: finding valuable knowledge from raw data.
Data Mining Tools
Numerous tools are available for data mining, each with unique capabilities.
| Tool | Capabilities |
|---|---|
| RapidMiner | Data preprocessing, modeling, evaluation, and deployment |
| Weka | Data preprocessing, classification, regression, clustering, and association rule mining |
| SPSS Modeler | Data preparation, modeling, and deployment |
| KNIME | Data integration, transformation, and visualization |
Applications of Data Mining
Data mining, the process of extracting knowledge from large datasets, has found widespread applications across various industries. Its ability to identify patterns, trends, and anomalies within data empowers organizations to make informed decisions, improve efficiency, and gain a competitive edge. From predicting customer behavior to uncovering hidden relationships in scientific research, data mining’s impact is profound.
Data Mining in Healthcare
Data mining in healthcare is revolutionizing patient care and medical research. By analyzing patient records, medical images, and clinical trials data, data mining algorithms can identify patterns indicative of diseases, predict patient outcomes, and personalize treatment plans. This leads to earlier diagnosis, more effective therapies, and improved patient management. For example, data mining can identify risk factors associated with specific diseases, allowing for proactive interventions and preventative measures.
Data Mining Applications in Finance
Data mining plays a critical role in the financial sector, enabling fraud detection, risk assessment, and investment strategies. By analyzing transaction data, market trends, and customer behavior, financial institutions can identify suspicious activities, assess creditworthiness, and optimize investment portfolios. For instance, data mining algorithms can detect fraudulent transactions by identifying unusual patterns in spending habits or transaction locations.
Data mining, essentially, is about uncovering hidden patterns in large datasets. It’s like sifting through a mountain of information to find the gold nuggets – and sometimes, unfortunately, it can be used to identify fraudulent schemes. For example, is paying to file taxes a scam? This question highlights how data mining techniques can be used to spot potentially problematic situations where people might be taking advantage of others.
Ultimately, understanding data mining helps us critically evaluate information and identify potential red flags in our daily lives.
Data Mining in Marketing and CRM
Data mining is crucial for effective marketing and customer relationship management (CRM). By analyzing customer data, companies can segment customers based on their preferences, tailor marketing campaigns, and improve customer satisfaction. This leads to increased sales, improved customer retention, and enhanced brand loyalty. Data mining can identify customer segments with high lifetime value, enabling targeted marketing campaigns that maximize return on investment.
Data Mining in Scientific Research
Data mining techniques are transforming scientific research across diverse disciplines. By analyzing complex datasets, researchers can discover hidden relationships, identify patterns, and generate new hypotheses. This can lead to breakthroughs in various fields, such as genomics, astronomy, and climate science. For example, data mining techniques can analyze large genomic datasets to identify genes associated with specific diseases.
Data Mining in Predicting Future Trends
Data mining techniques are increasingly used to predict future trends. By identifying patterns and anomalies in historical data, data mining algorithms can forecast future events, such as sales figures, market fluctuations, or customer behavior. This predictive capability allows businesses to proactively adapt to changing conditions and make informed decisions. For example, retailers can use data mining to predict seasonal demand for products, allowing them to optimize inventory levels and maximize sales.
Industries and Their Applications
| Industry | Specific Applications |
|---|---|
| Retail | Demand forecasting, inventory management, targeted marketing, customer segmentation |
| Telecommunications | Customer churn prediction, network optimization, fraud detection |
| Insurance | Risk assessment, claim fraud detection, pricing optimization |
| Manufacturing | Predictive maintenance, quality control, process optimization |
| Banking | Fraud detection, credit risk assessment, loan approval |
Data Mining Process and Evaluation
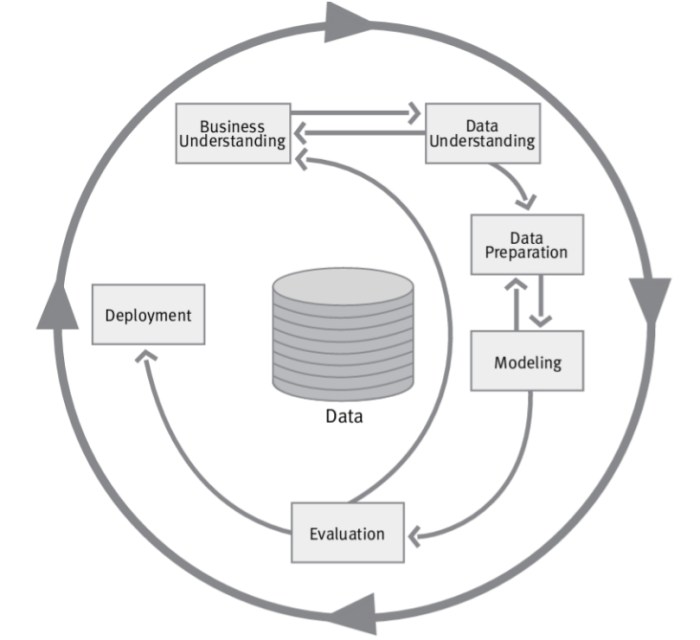
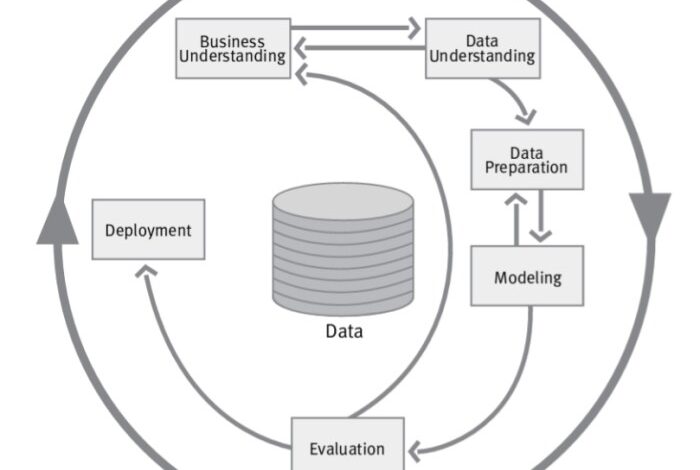
Data mining is more than just applying algorithms to data; it’s a structured process that involves several key phases. Understanding these phases, coupled with effective evaluation methods, is crucial for extracting meaningful insights and making sound decisions based on the results. This section delves into the steps involved in a typical data mining process and explains how to evaluate the effectiveness of the models built.
Phases in a Typical Data Mining Process
The data mining process is iterative and adaptable. It rarely follows a rigid, linear path, but instead, cycles through different stages to refine the models and improve the accuracy of the results.
- Problem Definition: Clearly defining the business problem is the foundation of a successful data mining project. This stage involves identifying the specific questions that need answering, the objectives, and the desired outcomes. A clear problem statement helps guide the subsequent steps and ensures that the analysis addresses the right issues.
- Data Collection and Preparation: Data is the lifeblood of data mining. This phase involves gathering relevant data from various sources, cleaning the data to handle missing values, inconsistencies, and errors, and transforming it into a usable format for the chosen algorithms. Careful data preparation significantly impacts the quality of the analysis results.
- Data Exploration and Visualization: Understanding the data is crucial before applying any data mining techniques. This stage involves examining the data’s characteristics, identifying patterns, and visualizing the relationships between variables. Exploratory data analysis helps in selecting the most appropriate data mining techniques.
- Model Building and Selection: In this phase, various data mining algorithms are applied to the prepared data to build predictive models. Choosing the most suitable algorithm depends on the type of data and the specific problem being addressed. Model selection often involves comparing different models’ performance and selecting the one that best fits the criteria.
- Model Evaluation and Refinement: This critical stage assesses the performance of the chosen model against established metrics. Identifying areas where the model underperforms and iteratively refining it through adjustments to the algorithms or data preparation techniques leads to more accurate and reliable results. Regular evaluation is vital for a successful data mining project.
- Deployment and Monitoring: The final stage involves integrating the model into the business processes and monitoring its performance over time. Adapting the model to changing business conditions and ensuring its continued accuracy is essential to maintaining its value. Monitoring ensures the model remains relevant and effective.
Methods for Evaluating Data Mining Models
Evaluating the effectiveness of data mining models is essential for determining their practical value. A range of metrics helps assess the model’s performance.
- Accuracy: Measures the proportion of correctly classified instances. High accuracy indicates a well-performing model that correctly predicts outcomes. Accuracy is calculated as the number of correctly classified instances divided by the total number of instances.
- Precision: Measures the proportion of correctly predicted positive instances out of all predicted positive instances. High precision indicates that the model is reliable in its positive predictions. Precision is calculated as the number of correctly predicted positive instances divided by the total number of predicted positive instances.
- Recall: Measures the proportion of correctly predicted positive instances out of all actual positive instances. High recall indicates that the model effectively captures all positive instances. Recall is calculated as the number of correctly predicted positive instances divided by the total number of actual positive instances.
- F1-score: Provides a balanced measure of precision and recall, offering a single metric to evaluate the model’s performance. The F1-score is calculated as 2
– (Precision
– Recall) / (Precision + Recall). - ROC Curve and AUC: The ROC (Receiver Operating Characteristic) curve plots the true positive rate against the false positive rate at various thresholds. The AUC (Area Under the Curve) value quantifies the model’s ability to distinguish between classes, providing a comprehensive measure of performance. A higher AUC indicates a better-performing model.
Interpreting and Using Data Mining Results
Data mining results should be interpreted within the context of the business problem. The insights gained must be translated into actionable strategies.
- Visualizations: Charts and graphs effectively communicate the trends and patterns revealed by data mining.
- Data Storytelling: Data mining results can be presented in a compelling narrative that highlights the key findings and their implications.
- Decision Support: Data mining results are crucial for informing business decisions, enabling better resource allocation, and improving operational efficiency.
Procedure for Implementing Data Mining Solutions
Implementing data mining solutions involves a structured approach that ensures successful integration into business operations.
- Project Initiation: Define the project scope, objectives, and resources.
- Data Acquisition and Preparation: Collect, clean, and transform data.
- Model Building and Evaluation: Build and evaluate data mining models using appropriate algorithms.
- Deployment and Monitoring: Integrate the model into business processes and monitor its performance.
Criteria for Selecting Data Mining Techniques
Choosing the right data mining technique is crucial for obtaining meaningful results.
| Criteria | Description |
|---|---|
| Problem Type | Classification, regression, clustering, association rule mining, etc. |
| Data Characteristics | Size, type, quality, dimensionality, and distribution of data. |
| Computational Resources | Availability of processing power and memory. |
| Interpretability | Clarity and ease of understanding the model’s results. |
| Performance Metrics | Accuracy, precision, recall, and other relevant metrics. |
Data Mining Tools and Technologies
Data mining, the process of extracting knowledge from large datasets, relies heavily on specialized tools and technologies. These tools streamline the entire data mining lifecycle, from data preprocessing to model deployment and evaluation. Choosing the right tools is crucial for effective data mining, as they directly impact the speed, accuracy, and efficiency of the entire process. This section delves into popular data mining software, cloud computing’s role, and emerging trends in the field.Data mining tools offer a wide array of functionalities, from data cleaning and transformation to advanced modeling and visualization.
Selecting the appropriate toolset depends on the specific data mining task, the size and complexity of the dataset, and the available resources. Different tools excel in different areas, allowing practitioners to tailor their approach to their particular needs.
Popular Data Mining Software and Tools
Several commercial and open-source data mining software packages are available, each with its strengths and weaknesses. These tools typically include functionalities for data preprocessing, model building, and evaluation. Some prominent examples include RapidMiner, WEKA, Orange, and SPSS Modeler. RapidMiner is a user-friendly visual platform for data mining tasks, while WEKA is known for its extensive collection of machine learning algorithms.
Orange is a powerful open-source tool that emphasizes data visualization and exploration. SPSS Modeler is a commercial product with a comprehensive set of data mining capabilities.
Data Mining Platforms
Data mining platforms provide a comprehensive environment for handling the entire data mining process. These platforms often include tools for data warehousing, data integration, data visualization, and model deployment. Examples include SAS Enterprise Miner, IBM SPSS Modeler, and Azure Machine Learning. These platforms typically offer a graphical user interface (GUI) for ease of use, along with a rich set of algorithms and analytical capabilities.
Features often include data preparation, predictive modeling, and deployment.
Role of Cloud Computing in Data Mining
Cloud computing plays an increasingly important role in data mining. Cloud-based platforms provide scalable and cost-effective infrastructure for handling massive datasets. This allows data mining projects to be conducted without significant upfront investment in hardware or software. Cloud-based data mining tools allow for parallel processing of large datasets, reducing the time required for data mining tasks.
Application of Big Data Technologies in Data Mining
Big data technologies, such as Hadoop and Spark, are essential for handling the massive datasets often encountered in modern data mining projects. Hadoop’s distributed file system and MapReduce framework allow for processing of extremely large volumes of data, while Spark offers faster in-memory processing capabilities. These technologies are crucial for handling the scale and velocity of big data, enabling faster insights and more accurate predictions.
Future Trends in Data Mining Tools and Technologies
Future data mining tools are expected to incorporate advanced techniques like deep learning, artificial intelligence, and natural language processing. These advancements will enable more sophisticated data mining tasks, such as identifying complex patterns, understanding customer behavior, and automating data analysis. Integration with other technologies, such as IoT and blockchain, will further expand the potential of data mining. Tools will likely become more user-friendly, offering visual interfaces and simplified workflows.
Comparison of Data Mining Software
| Software | Features | Pros | Cons |
|---|---|---|---|
| RapidMiner | Visual interface, extensive algorithm library, easy to learn | Ease of use, versatility | Limited scalability for very large datasets |
| WEKA | Open-source, extensive machine learning algorithms | Cost-effective, highly customizable | Steeper learning curve |
| Orange | Data visualization, interactive exploration | Intuitive, user-friendly, emphasis on exploration | Limited modeling capabilities compared to others |
| SPSS Modeler | Comprehensive data mining capabilities, robust algorithms, deployment features | Extensive functionalities, advanced algorithms | Commercial, potentially high cost |
Closing Summary: Definition Of Data Mining
In conclusion, data mining is a multi-faceted discipline that transcends industries and applications. Its ability to uncover hidden patterns and trends within large datasets has significant implications for various sectors. From the initial stages of data preprocessing to the final evaluation and interpretation of results, each step in the data mining process is crucial. Understanding the fundamental concepts, techniques, and tools associated with data mining empowers individuals and organizations to leverage this powerful technology for better decision-making and innovation.