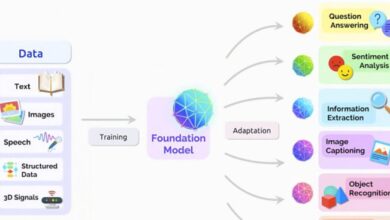
Definition of machine learning: Unlocking the secrets of how computers learn without explicit programming. This exploration delves into the core concepts, historical evolution, and practical applications of machine learning. From the fundamental differences between machine learning and traditional programming to the various types of machine learning (supervised, unsupervised, and reinforcement), we’ll uncover the intricate mechanisms behind this transformative technology.
This in-depth look at machine learning will cover its historical context, examining key milestones and influential figures. We’ll also explore the key concepts and algorithms, including linear regression, decision trees, and support vector machines. Moreover, the practical applications of machine learning across diverse industries like healthcare, finance, and retail will be highlighted, along with a step-by-step guide on building a simple machine learning model.
Finally, we’ll address the challenges and future directions of this rapidly evolving field, emphasizing the importance of ethical considerations and human oversight.
Defining Machine Learning
Machine learning is a rapidly evolving field that empowers computers to learn from data without explicit programming. It’s fundamentally different from traditional programming, which relies on pre-defined rules and instructions. Instead, machine learning algorithms identify patterns, make predictions, and improve their performance over time through exposure to data. This adaptability makes machine learning crucial for tackling complex problems in diverse fields.This ability to learn from data, rather than being explicitly programmed, is the core difference that sets machine learning apart from traditional programming.
Instead of a rigid set of rules, machine learning algorithms adjust their internal parameters based on the input data, allowing them to adapt and improve their performance as they process more data. This iterative refinement is key to machine learning’s success in areas like predictive maintenance, fraud detection, and personalized recommendations.
Defining Machine Learning
Machine learning is a branch of artificial intelligence that enables computer systems to learn from data without being explicitly programmed. It involves developing algorithms that allow computers to identify patterns, make predictions, and improve their performance over time through experience with data. This learning process occurs through the analysis of input data and the adjustment of internal parameters to achieve optimal performance.
Fundamental Differences Between Machine Learning and Traditional Programming
Traditional programming involves explicitly defining the steps and rules for a computer to follow. In contrast, machine learning algorithms learn from data, adjusting their internal parameters to optimize their performance. Traditional programming excels at tasks with clear, pre-defined procedures, while machine learning shines in areas with complex, evolving patterns and relationships. For example, a program to calculate the area of a circle requires explicit instructions on how to use the formula, whereas a machine learning model to detect spam in emails learns the characteristics of spam from past examples.
Types of Machine Learning
Machine learning algorithms can be categorized into different types, each with unique characteristics and applications. These categories reflect the nature of the data used and the learning process involved.
- Supervised Learning: In supervised learning, algorithms learn from labeled data, where each data point is associated with a known output. The goal is to learn a mapping from input to output, allowing the algorithm to predict the output for new, unseen inputs. Examples include spam detection, where emails are labeled as spam or not spam, and image recognition, where images are labeled with the objects they contain.
- Unsupervised Learning: Unsupervised learning algorithms operate on unlabeled data, aiming to discover hidden patterns and structures within the data. Examples include customer segmentation, where customers are grouped based on their purchasing behavior, and anomaly detection, where unusual data points are identified.
- Reinforcement Learning: In reinforcement learning, an agent interacts with an environment, receiving rewards or penalties for its actions. The goal is to learn a policy that maximizes the cumulative reward over time. Examples include game playing, where the agent learns optimal strategies to win, and robotics, where the agent learns to navigate and perform tasks.
Examples of Machine Learning Applications
Machine learning has widespread applications across various fields. In healthcare, it aids in disease diagnosis and treatment prediction. In finance, it detects fraudulent transactions and assesses investment risks. In marketing, it personalizes recommendations and targets specific customer segments. In manufacturing, it optimizes production processes and predicts equipment failures.
Comparison of Machine Learning Types
The table below highlights the key differences between supervised, unsupervised, and reinforcement learning methods.
| Feature | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data | Labeled data | Unlabeled data | Interaction with environment |
| Goal | Predict outcomes | Discover patterns | Learn optimal actions |
| Example | Spam detection | Customer segmentation | Game playing |
Historical Context of Machine Learning
Machine learning, a field rapidly transforming industries and our daily lives, has a rich and fascinating history. Its evolution reflects the interplay of theoretical advancements, computational power, and the growing need to automate complex tasks. From its humble beginnings in the mid-20th century to the sophisticated algorithms powering modern applications, machine learning’s journey is a testament to human ingenuity and the relentless pursuit of intelligent systems.Early explorations of machine learning were rooted in the desire to mimic human cognitive processes.
Researchers sought to create systems capable of learning from data, adapting to new information, and improving their performance over time. This quest was initially limited by the computational resources available, but as technology progressed, the field flourished.
Early Approaches to Machine Learning
Early machine learning approaches focused on relatively simple algorithms and datasets. Rule-based systems and decision trees were popular methods for classifying data and making predictions. These methods, while rudimentary by today’s standards, laid the foundation for more sophisticated techniques. The limited computational power of the time restricted the complexity of models, and data sets were often smaller and less varied than what is available today.
Key Milestones and Influential Figures
The development of machine learning has been driven by numerous influential figures and significant milestones. One pivotal moment was the invention of the perceptron in the 1950s, a simple neural network model that marked an early attempt at creating artificial neural networks. This work, spearheaded by Frank Rosenblatt, demonstrated the potential for learning from data. Later, the development of support vector machines (SVMs) in the 1990s by researchers like Vladimir Vapnik revolutionized classification tasks.
Machine learning, essentially, is about teaching computers to learn from data without explicit programming. It’s fascinating how this concept is being applied in various fields, even impacting discussions surrounding character portrayals in video games like in the recent controversy surrounding Abby in The Last of Us, specifically, Kaitlyn Dever’s portrayal. Ultimately, the definition of machine learning is about creating systems that can adapt and improve their performance over time, a concept with vast potential in many areas.
These methods, along with others like decision trees and Bayesian networks, demonstrated the power of machine learning in various applications.
Impact of Computational Power
The exponential growth in computational power has been a crucial factor in the evolution of machine learning. Early algorithms were limited by the speed and memory of available computers. As computers became faster and more powerful, more complex algorithms could be implemented and trained on larger datasets. This led to a significant leap in the performance and capabilities of machine learning models.
A Timeline of Significant Events
- 1950s: The perceptron, a foundational neural network model, is invented by Frank Rosenblatt. Early research focuses on rule-based systems and decision trees for pattern recognition.
- 1960s-1970s: The field experiences a period of relative stagnation due to the limitations of computational power and the difficulty in finding suitable datasets.
- 1980s: Expert systems and knowledge-based systems gain prominence, representing an early form of knowledge representation in AI. Machine learning techniques are further developed and refined, although their use remains limited.
- 1990s: Support vector machines (SVMs) are developed, revolutionizing classification tasks. The internet’s growth provides access to massive datasets, fueling further research and development.
- 2000s-Present: The availability of powerful computing resources, vast datasets (Big Data), and advanced algorithms like deep learning models lead to breakthroughs in various applications, including image recognition, natural language processing, and autonomous vehicles.
Comparison of Early and Modern Techniques
Early machine learning techniques, such as decision trees and rule-based systems, were simpler and less computationally intensive. Modern techniques, including deep learning and neural networks, are more complex and capable of handling larger, more intricate datasets. This increased complexity allows for the development of sophisticated models that can learn intricate patterns and relationships within data. The impact of these advanced models is reflected in the high accuracy of modern applications like image recognition and natural language processing.
Key Concepts and Algorithms
Machine learning algorithms are the heart of any machine learning system. They are the sets of rules and procedures that allow computers to learn from data without being explicitly programmed. Understanding the core concepts and different algorithms available is crucial for anyone wanting to work with machine learning. This section dives into the fundamental building blocks and popular choices in the field.
Core Concepts
Machine learning algorithms rely on various core concepts. Data preprocessing, often the first step, involves cleaning, transforming, and preparing the data for model training. Feature engineering is another critical aspect, focusing on extracting relevant information from raw data to improve model performance. Model evaluation is essential for assessing the quality of a trained model, with metrics like accuracy, precision, and recall being commonly used.
These concepts, combined with the algorithms themselves, empower machines to learn from data and make predictions or decisions.
The Role of Data
Data is the lifeblood of machine learning models. The quality, quantity, and relevance of the data directly impact the model’s performance. A large dataset with diverse and representative examples is often crucial for training robust models. Data preprocessing techniques, such as handling missing values or outliers, are essential to ensure data quality. Features within the data must be carefully selected and engineered to ensure the model learns the relevant patterns and avoids overfitting to noise in the data.
Machine Learning Algorithms
A wide variety of machine learning algorithms exist, each with its strengths and weaknesses. Understanding these differences is essential for choosing the right algorithm for a particular task.
- Linear Regression: This supervised learning algorithm models the relationship between a dependent variable and one or more independent variables by fitting a linear equation to observed data. It’s widely used for predicting continuous values, such as house prices or stock prices. A simple example would be predicting the price of a house based on its size and location.
The algorithm finds the best-fitting line through the data points, minimizing the difference between the predicted and actual values. Linear Regression’s strength lies in its simplicity and ease of interpretation, but it can struggle with complex relationships between variables.
- Decision Trees: Decision trees are a supervised learning method used for both classification and regression tasks. They create a tree-like model of decisions and their possible consequences, ultimately leading to a prediction. For instance, in image classification, a decision tree can analyze pixel values to categorize an image. Decision trees are easily interpretable and can handle both numerical and categorical data.
However, they can be prone to overfitting, particularly with complex datasets.
- Support Vector Machines (SVMs): SVMs are supervised learning models used for classification and regression tasks. They work by finding the optimal hyperplane that maximizes the margin between different classes in the data. In spam detection, SVMs can classify emails as spam or not spam based on features like the presence of specific words or phrases. SVMs are effective in high-dimensional spaces and can handle non-linear relationships.
However, they can be computationally expensive for large datasets and require careful tuning of parameters.
Comparison of Algorithms
Different machine learning algorithms have varying strengths and weaknesses. Linear regression is straightforward but may not capture complex relationships. Decision trees are easy to interpret but can overfit to training data. SVMs are effective in high-dimensional spaces but require more computational resources. The choice of algorithm depends heavily on the specific problem, the characteristics of the data, and the desired level of performance and interpretability.
Summary Table, Definition of machine learning
| Algorithm | Type | Application |
|---|---|---|
| Linear Regression | Supervised | Predicting house prices, sales forecasting |
| Decision Trees | Supervised | Image classification, medical diagnosis |
| Support Vector Machines | Supervised | Spam detection, face recognition |
Machine Learning in Practice
Machine learning is no longer a theoretical concept; it’s transforming industries and impacting our daily lives. From personalized recommendations on streaming services to fraud detection in financial transactions, machine learning models are powering a multitude of applications. This section delves into the practical application of machine learning, exploring the model-building process, data considerations, and ethical implications.Building a machine learning model is a multi-step process, starting with data acquisition and culminating in model deployment and evaluation.
Each stage presents unique challenges and opportunities, and understanding these intricacies is crucial for successful implementation. We’ll examine the vital role of data preprocessing and feature engineering, and the ethical responsibilities that accompany the use of machine learning models.
Real-World Applications of Machine Learning
Machine learning is being utilized in a vast array of sectors. Predictive maintenance in manufacturing, personalized medicine in healthcare, and targeted advertising in e-commerce are just a few examples. These applications leverage machine learning’s ability to identify patterns and make predictions from data, leading to significant improvements in efficiency, accuracy, and decision-making. For example, in the manufacturing industry, machine learning algorithms can analyze sensor data from equipment to predict potential failures before they occur, allowing for proactive maintenance and minimizing downtime.
The Machine Learning Model Building Process
The process of building a machine learning model typically involves several key steps. Data collection, cleaning, and preparation are fundamental to ensuring the model’s accuracy. Selecting the appropriate algorithm and training the model with the prepared data are crucial steps. Finally, evaluating the model’s performance and deploying it for real-world use are critical to ensure its effectiveness.
Machine learning, simply put, is about teaching computers to learn from data without explicit programming. It’s a fascinating field, but ultimately, the impact of machine learning relies heavily on how we use it. Just like the importance of individual action, as explored in the individual action matters essay , the choices we make about deploying these technologies are crucial.
This highlights the ethical considerations behind machine learning definitions and applications.
- Data Collection: Gathering relevant data is the first step. This could involve extracting data from databases, APIs, or web scraping. The quality and quantity of data directly impact the model’s performance. For instance, a model predicting customer churn needs historical data on customer behavior, demographics, and service interactions.
- Data Preprocessing: Raw data often contains inconsistencies, missing values, and irrelevant features. Data preprocessing techniques, such as handling missing values, outlier removal, and feature scaling, are essential for improving model accuracy. For example, if a dataset has missing values for customer income, imputation methods can be used to estimate these values.
- Feature Engineering: Creating new features from existing ones can significantly improve a model’s predictive power. Feature engineering involves transforming and combining existing features to create more meaningful variables. For example, from date of birth, we can derive age, which might be a more informative feature than the original date of birth.
- Model Selection: Choosing the right machine learning algorithm depends on the nature of the problem and the available data. Different algorithms are suitable for different tasks. For example, linear regression is well-suited for predicting continuous values, while decision trees are useful for classification problems.
- Model Training: Training the model involves feeding the prepared data to the selected algorithm. The algorithm learns patterns and relationships from the data, ultimately producing a model that can make predictions. This is akin to teaching a student to solve math problems; the model learns from the examples provided.
- Model Evaluation: Evaluating the model’s performance is critical. Metrics such as accuracy, precision, recall, and F1-score are used to assess the model’s effectiveness. A model that predicts customer churn with 90% accuracy is more reliable than one with 50% accuracy.
- Model Deployment: Deploying the model involves integrating it into a production environment, allowing it to make predictions on new, unseen data. This could involve deploying the model as a web service or integrating it into an existing application. For instance, a deployed model can predict customer churn in real-time, enabling proactive intervention.
Ethical Considerations in Machine Learning
Machine learning models can perpetuate existing biases present in the data they are trained on. This can lead to unfair or discriminatory outcomes. Therefore, careful consideration of the ethical implications of machine learning is essential. Understanding and mitigating biases in data, ensuring fairness and transparency in model design, and establishing accountability mechanisms are critical to responsible machine learning development.
Building a Simple Machine Learning Model (Customer Churn Prediction)
This example demonstrates a simple machine learning model for predicting customer churn. The model aims to identify customers likely to cancel their subscription.
- Data Collection: Gather historical data on customer behavior, demographics, and subscription details.
- Data Preprocessing: Clean and prepare the data by handling missing values and converting categorical features into numerical ones. For instance, convert “payment method” (e.g., credit card, debit card) into numerical values.
- Feature Engineering: Create new features, such as the duration of the subscription, average monthly spending, and frequency of customer interaction.
- Model Selection: Choose a suitable classification algorithm, such as logistic regression or a decision tree.
- Model Training: Train the model using the prepared data, splitting it into training and testing sets. The training set is used to train the model, while the testing set evaluates its performance.
- Model Evaluation: Evaluate the model’s performance using appropriate metrics like accuracy, precision, and recall.
- Model Deployment: Deploy the model to predict customer churn in real-time, allowing for proactive interventions to retain customers.
Applications of Machine Learning: Definition Of Machine Learning
Machine learning is no longer a futuristic concept; it’s rapidly transforming industries and impacting our daily lives. From personalized recommendations to complex medical diagnoses, the applications of machine learning are vast and varied. This section explores the diverse ways machine learning is being implemented across different sectors, highlighting its potential to solve complex problems and shape the future.
Transforming Healthcare
Machine learning is revolutionizing healthcare by enabling faster and more accurate diagnoses, personalized treatment plans, and improved drug discovery. Algorithms can analyze vast amounts of medical data, including patient history, genetic information, and imaging scans, to identify patterns and predict potential health risks. This predictive capability can help doctors proactively intervene and prevent diseases.
- Disease Prediction: Machine learning algorithms can analyze patient data to identify patterns associated with specific diseases, allowing for early detection and intervention. For example, analyzing medical images (X-rays, CT scans) can help detect cancerous tumors at earlier stages, increasing the chances of successful treatment. A study by researchers at Stanford University found that machine learning models could accurately identify diabetic retinopathy from retinal images with a high degree of accuracy, which could lead to timely interventions.
- Personalized Treatment: Machine learning can help tailor treatment plans to individual patients based on their specific genetic makeup, medical history, and response to previous treatments. This personalized approach can lead to more effective treatments and fewer side effects. For example, certain cancer treatments may have different outcomes depending on a patient’s genetic profile; machine learning can help determine the optimal treatment strategy for each patient.
Machine learning, simply put, is about teaching computers to learn from data without explicit programming. This mirrors the complexities of English spelling, which, as highlighted in this fascinating essay on english spelling mess essay , demonstrates the unpredictable nature of language rules. Ultimately, both machine learning and language evolution are about patterns in data, and how these patterns can be leveraged for understanding and prediction.
- Drug Discovery: Machine learning is accelerating the drug discovery process by identifying potential drug candidates and predicting their efficacy and safety. This process can significantly reduce the time and cost associated with developing new drugs. Companies like Atomwise are using machine learning to predict the binding affinity of molecules to target proteins, a crucial step in drug development.
Revolutionizing Finance
The financial sector is another area where machine learning is making a significant impact. Machine learning algorithms are used for fraud detection, risk assessment, algorithmic trading, and customer service. The ability to process vast amounts of financial data quickly and accurately enables financial institutions to make better decisions and mitigate risks.
- Fraud Detection: Machine learning models can analyze transaction data to identify unusual patterns and flag potentially fraudulent activities. This proactive approach can prevent financial losses and protect customers. Banks frequently use machine learning to detect unusual transaction patterns, such as large sums of money transferred to unfamiliar accounts, which may indicate fraudulent activity.
- Risk Assessment: Machine learning algorithms can assess the risk associated with various financial instruments and investments, enabling investors to make informed decisions. This includes evaluating creditworthiness and predicting potential market fluctuations.
- Algorithmic Trading: High-frequency trading firms use machine learning algorithms to execute trades at lightning speed, potentially generating substantial profits. These algorithms analyze market data and identify opportunities for quick trades.
Transforming Retail
Machine learning is also transforming the retail sector by providing personalized recommendations, optimizing inventory management, and improving customer service. By analyzing customer data, retailers can understand their preferences and tailor their offerings to individual needs.
- Customer Recommendations: Machine learning algorithms can analyze customer browsing history, purchase patterns, and demographics to suggest relevant products. This personalized approach can increase sales and improve customer satisfaction. E-commerce platforms frequently use recommendation systems based on machine learning algorithms.
- Inventory Management: Machine learning can optimize inventory levels by predicting future demand and adjusting stock levels accordingly. This can help retailers avoid overstocking or understocking, reducing costs and improving efficiency. A retailer may use machine learning to forecast the demand for certain products based on past sales data, seasonality, and other factors.
- Personalized Marketing: Machine learning algorithms can target specific customer segments with personalized marketing campaigns, improving the effectiveness of marketing efforts. This can lead to higher conversion rates and increased revenue.
Emerging Trends
The field of machine learning is constantly evolving, with new applications and trends emerging all the time. These include the use of machine learning in autonomous vehicles, personalized medicine, and environmental monitoring. The ability to analyze large datasets and identify patterns is revolutionizing many fields.
| Industry | Application | Example |
|---|---|---|
| Healthcare | Disease prediction | Identifying patterns in medical images |
| Finance | Fraud detection | Identifying suspicious transactions |
| Retail | Customer recommendation | Suggesting products based on browsing history |
| Transportation | Autonomous vehicles | Self-driving cars |
Challenges and Future Directions
Machine learning, while revolutionizing various fields, faces significant hurdles. Understanding these limitations and potential solutions is crucial for responsible and effective deployment. This section delves into current challenges, model limitations, and future research directions, highlighting the crucial role of human oversight in mitigating risks.The increasing complexity of machine learning models, often involving millions of parameters, can lead to opacity, making it difficult to understand how these models arrive at their decisions.
This “black box” nature raises concerns about trustworthiness and accountability, particularly in critical applications like healthcare or finance. Furthermore, biases present in training data can perpetuate and even amplify societal inequalities within the output of the models. Addressing these challenges is vital for ensuring equitable and responsible use of machine learning.
Current Challenges in Machine Learning
The development and deployment of machine learning models face several key challenges. Data quality and availability are paramount. Insufficient or biased training data can lead to inaccurate or unfair predictions. Furthermore, the computational cost of training complex models can be prohibitive, particularly for resource-constrained environments. The need for skilled personnel to develop, deploy, and maintain these systems is another crucial consideration.
- Data Quality and Availability: Insufficient data or data with inherent biases can lead to flawed models. For instance, if a facial recognition system is trained primarily on images of light-skinned individuals, it may perform poorly on images of darker-skinned individuals. Data augmentation techniques and careful data selection are vital for mitigating these issues.
- Computational Cost: Training sophisticated models like deep neural networks requires substantial computing power and time. This is a significant barrier for researchers and organizations with limited resources. The use of cloud computing and optimized algorithms is crucial to address this challenge.
- Lack of Skilled Personnel: The development, deployment, and maintenance of machine learning systems require specialized expertise. The demand for skilled machine learning engineers and data scientists often outstrips the supply, creating a talent gap.
Limitations of Machine Learning Models
Machine learning models are not infallible. They can be susceptible to errors, especially when dealing with complex or unseen data. Overfitting, where a model learns the training data too well, leading to poor generalization on new data, is a common issue. Another limitation is the difficulty in interpreting the reasoning behind model predictions. This “black box” nature hinders trust and transparency.
- Overfitting: A model that learns the training data too well can perform poorly on new, unseen data. Techniques like regularization and cross-validation can help mitigate overfitting.
- Lack of Explainability: Understanding the decision-making process of complex models is challenging. Methods like feature importance analysis and model interpretability tools are essential for gaining insights into the model’s predictions.
- Sensitivity to Data Distribution Shifts: Models trained on one data distribution may not perform well when applied to a different distribution. Robustness to data variations is a critical concern in real-world applications.
Potential Future Directions in Machine Learning
Research in machine learning is constantly evolving. Areas like federated learning, which allows training models on decentralized data without compromising privacy, hold significant promise. Explainable AI (XAI) aims to make model decisions more understandable and transparent, boosting trust and accountability. Furthermore, reinforcement learning, where agents learn through trial and error, is finding applications in robotics and game playing.
- Federated Learning: This approach enables training models on distributed data sources without transferring the data itself. This protects privacy and enhances efficiency in scenarios like mobile device data analysis.
- Explainable AI (XAI): This research area focuses on developing methods for interpreting model predictions and understanding how models arrive at their decisions. This is crucial for building trust and accountability in AI systems.
- Reinforcement Learning: This area focuses on training agents to make sequential decisions in an environment. This has applications in robotics, game playing, and resource management.
The Role of Human Oversight in Machine Learning Systems
Human oversight is critical in the development and deployment of machine learning systems. Humans should be involved in the data preparation, model selection, evaluation, and interpretation of results. Human intervention is crucial to address potential biases, ensure ethical considerations, and maintain control in critical applications.
- Data Preprocessing: Humans need to actively participate in data cleaning and preprocessing steps to ensure the data is accurate, unbiased, and suitable for model training.
- Model Evaluation and Monitoring: Regular evaluation and monitoring of the model’s performance are necessary to identify and address any issues or biases.
- Addressing Bias: Careful consideration of potential biases in training data is crucial. Humans should actively work to identify and mitigate biases to ensure fair and equitable outcomes.
Potential Solutions to Mitigate Risks
To mitigate the risks associated with using machine learning models, a multi-faceted approach is needed. This includes rigorous testing, continuous monitoring, and transparent communication. Furthermore, developing robust evaluation metrics and promoting responsible development practices are crucial.
- Rigorous Testing and Validation: Thorough testing on diverse and representative datasets is essential to identify potential issues and ensure the model’s robustness.
- Continuous Monitoring and Feedback Loops: Models should be continuously monitored to detect and address unexpected behavior or performance degradation.
- Promoting Responsible Development Practices: Adherence to ethical guidelines and best practices in machine learning development is essential to ensure responsible deployment.
Closing Notes

In conclusion, machine learning is a powerful tool with the potential to revolutionize numerous aspects of our lives. By understanding its core principles, historical context, and practical applications, we can appreciate its profound impact on various industries and the exciting possibilities it unlocks for the future. This exploration provided a comprehensive overview, from the definition to the future directions of machine learning, enabling a deeper understanding of this transformative technology.